추천시스템에 대한 개념을 익히고 실습했다.
생각보다 추천시스템의 역사가 오래되었고 방식도 다양하다는 점이 재미있었다.
추천 시스템
정보 필터링(IF) 기술의 일종으로, 특정 사용자가 관심을 가질만한 정보를 추천하는 것
크게 콘텐츠 기반 필터링(Content based filtering) 방식과 협업 필터링(Collaborative filtering) 방식이 있다.
추천 시스템의 예시로 카메라를 구매한다고 가정했을 때, 비슷한 카메라들을 보여준다든지 카메라 가방, 렌즈 등 관련 용품을 보여주는 형태가 된다.
추천 시스템의 역사
1. 2005 ~ 2010 : 연관 상품 추천
- Apriori 알고리즘, 빈번한 항목 집합 분석 및 연관 규칙 학습
2. 2010 ~ 2015 : 협업 필터링
- 축적된 사용자 행동 데이터를 기반으로 사용자의 선호도 예측
3. 2013 ~ 2017 : 빅데이터
- FP-Growth, 트리구조를 이용하여 Apriori의 연산 속도를 보완
4. 2015 ~ 2017 : 딥러닝
- 일종의 규칙 모음, 텍스트 임베딩 기법
5. 2017 ~ : 개인화 추천 시스템
- user~item 간의 관계가 드러날 수 있는 특징 벡터 생성, 개인별 순위 구현
콘텐츠 기반 필터링 방식
- 소비한 콘텐츠를 기준으로 유사한 특성을 가진 콘텐츠를 추천
- 사용자가 과거에 좋아했거나 현재 검토 중인 항목과 유사한 항목을 추천
모델 이론
데이터 습득 -> 콘텐츠 분석 -> 유저 프로필 파악 -> 유사 아이템 선택
협업 필터링 방식
- 유저와 아이템 간의 관계만 사용
- 사용자와 같은 생각의 다른 사용자의 견해에 따라 제품을 추천
- 다른 사용자와의 비슷함에 기초를 둔다
모델 이론
행동에 대한 데이터 수집 및 분석, 사용자의 활동과 다른 사용자와의 유사성을 기반으로 예측
콘텐츠 기반 추천 시스템
데이터 준비
kaggle의 Online retail dataset을 사용하여 실습한다.
df = pd.read_csv(f"data/retail/online_retail.csv") df.shape # 실행 결과 (541909, 8)
online retail 데이터 로드

온라인 거래 데이터셋이다.
샘플링
df = df[df["Description"].notnull() & (df["Description"].str.len() > 2) ].sample(10000, random_state=42).copy() df["Description"] = df["Description"].str.upper()
원본 데이터가 매우 크기 때문에 Description이 null이 아니면서 2글자가 넘는 데이터 중 10000개만 추출해서 사용한다. 대소문자가 섞인 것을 생각하여 대문자로 통일한다.
TF-IDF
자연어 처리에선 기계가 자연어를 이해할 수 있도록 수치화하는 과정이 반드시 필요하다. 사이킷런은 TF-IDF를 자동 계산해 주는 TfidfVectorizer를 제공한다.
from sklearn.feature_extraction.text import TfidfVectorizer tfidfvect = TfidfVectorizer(max_features=2000, lowercase=False) tfidf_overview = tfidfvect.fit_transform(df['Description']) df_tfidf = pd.DataFrame(tfidf_overview.toarray(), columns=tfidfvect.get_feature_names_out()) df_tfidf
TfidfVectorizer를 불러오고 객체를 생성한다. 이를 이용해 Description을 tf-idf 벡터화한다.
아래는 벡터화 결과를 데이터프레임으로 변환한 결과다.
매우 sparse한 것을 확인할 수 있다.
유사도
코사인 유사도(Cosine Similarity) : 내적 공간 내에서 두 벡터 사이의 코사인 각도를 구하는 방법. 벡터의 크기가 아닌 방향의 유사도를 판단하는 목적으로 사용된다. 완전히 같은 방향일 경우 1, 반대 방향일 경우 -1의 값을 가진다.
사이킷런은 코사인 유사도를 계산해 주는 cosine_similarity를 제공한다.
from sklearn.metrics.pairwise import cosine_similarity cosine_matrix = cosine_similarity(tfidf_overview, tfidf_overview) cosine_matrix
상관계수와 유사하다. 코사인 유사도가 높으면 비슷한 콘텐츠로 생각할 수 있다.
sns.heatmap(cosine_matrix[:100, :100], vmin=-1, vmax=1, cmap='coolwarm')seaborn의 heatmap으로 코사인 유사도 시각화(100개)
자기 자신과는 당연하게도 코사인 유사도가 1이다.
df_cosine = pd.DataFrame(cosine_matrix, index=df.index, columns=df.index) df_cosine
각 Description간의 유사도를 나타내는 데이터프레임
특정 제품과 유사한 제품 찾기
item = "GLASS" item_id = df.loc[df["Description"].notnull() & df["Description"].str.contains(item), "Description"].index[-1]
예시로 'GLASS'가 들어간 제품 하나를 선정했다.
해당 제품과 유사도 Top 10 제품 찾기
df_cosine.loc[df_cosine[item_id] < 1, item_id].drop_duplicates().nlargest(10)1은 자기 자신과 같음을 의미하므로 1보다 작게, 중복을 제거한다.
sim_df_index = df_cosine.loc[df_cosine[item_id] < 1, item_id].drop_duplicates().nlargest(10).index df.loc[sim_df_index, ['StockCode', 'Description']]
인덱스를 이용하여 StockCode와 Description을 확인한다.
AMBER BERTIE GLASS BEAD BAG CHARM과 유사한 제품 10개를 찾았다.
제품 추천 과정을 함수로 만들어 보자.
def find_item(title, df_cosine, df): try: df_id = df[df["Description"].str.contains(title.upper())].index[0] print(f'{df.loc[df_id, "Description"]} 관련 제품을 추천합니다') df_item = df_cosine[df_id].drop_duplicates() recomm_idx = df_item[df_item < 1].nlargest(10).index recomm_item = df.loc[recomm_idx, ["Description"]] return recomm_item except: return f'{title} 관련 제품 없음'
특정 제품을 선정하고 관련된 제품을 10개 추천하는 함수를 작성했다. 관련 제품이 없는 경우에 대한 예외처리를 했다.
title = "card" find_item(title, df_cosine, df)
관련 제품이 있는 경우
title = "hihello" find_item(title, df_cosine, df) # 실행 결과 'hihello 관련 제품 없음'
관련 제품이 없는 경우 메시지 출력
유클리디안 유사도
유클리드 거리(Euclidean distance)는 두 점 사이의 거리를 계산할 때 흔히 쓰는 방법으로 유클리드 공간에서 기하학적 최단 거리를 의미한다.
즉 유클리드 거리 값이 가장 작다는 것은 문서 간 거리가 가장 가깝다는 것이고 유사하다는 의미다.
from sklearn.metrics.pairwise import euclidean_distances ec_matrix = euclidean_distances(tfidf_overview, tfidf_overview) ec_matrix = ec_matrix / ec_matrix.max() ec_matrix.min(), ec_matrix.max() # 실행 결과 (0.0, 1.0)
유클리디안 유사도 행렬을 만들고 값을 0~1로 만들었다.
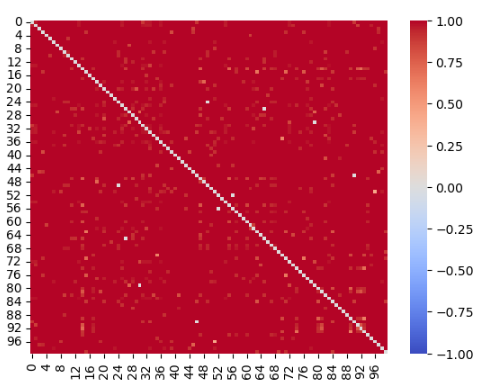
자기 자신과의 유클리디안 거리는 0이 된다.
def find_item_ec(title, df_ec_matrix, df): try: df_id = df[df["Description"].str.contains(title.upper())].index[0] print(f'{df.loc[df_id, "Description"]} 관련 제품을 추천합니다') df_item = df_ec_matrix[df_id].drop_duplicates() recomm_idx = df_item[df_item > 0].nsmallest(10).index recomm_item = df.loc[recomm_idx, ['StockCode', "Description"]] return recomm_item except: return f'{title} 관련 제품 없음'
유클리디안 거리를 이용하여 제품을 추천하는 함수 작성
title = "mug" find_item_ec(title, df_ec_matrix, df)
타이틀 mug 지정
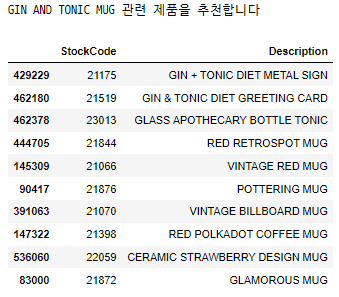
GIN AND TONIC MUG 관련 제품이 추천되었다.
피어슨 유사도
두 벡터가 주어졌을 때의 상관관계를 계산
pearson_sim = np.corrcoef(tfidf_overview.toarray()) pearson_sim[:100, :100]
numpy corrcoef 함수로 계산 후 일부 확인
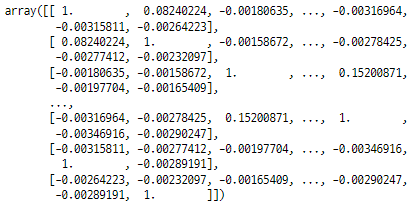
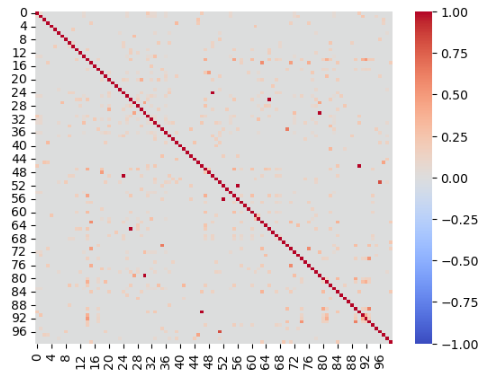
pandas의 상관계수 구하는 함수를 사용해도 같은 결과를 얻는다. 자기 자신과의 피어슨 유사도는 1이 된다.
title = "LANTERN" find_item_corr(title, df_pearson_sim, df)
피어슨 유사도를 이용한 제품 추천 함수를 만들고 테스트
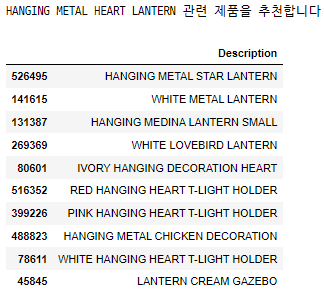
HANGING METAL HEART LANTERN 관련 제품이 추천되었다.
자카드 유사도
자카드 지수(Jaccard index)는 0과 1 사이 값을 가지고, 두 집합이 동일하면 1의 값을 가지며 공통의 원소가 하나도 없으면 0의 값을 가진다. 얼마나 많은 아이템을 동시에 갖고 있는가?를 수치로 환산하는 형태이다.
from sklearn.metrics.pairwise import pairwise_distances jac_matrix = pairwise_distances(tfidf_overview.toarray(), metric='jaccard') jac_matrix
sklearn의 함수로 자카드 유사도를 구한다. metric을 지정하지 않으면 기본값인 유클리디안 거리가 계산된다.

title = "card" find_item_jac(title, df_jac_matrix, df)
자카드 유사도를 이용한 제품 추천 함수를 만들고 테스트

THE PARTY BIRTHDAY CARD 관련 제품이 추천되었다.
이렇게 코사인 유사도, 유클리디안 유사도, 피어슨 유사도, 자카드 유사도를 활용한 콘텐츠 기반 추천시스템을 실습하며 이해해 봤다. 이후 협업 필터링 기반 추천시스템도 실습하고 하루가 지나갔다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 86] 파이널프로젝트 시작 - 데이터 수집 (0) | 2023.04.27 |
|---|---|
| [DAY 85] AI School 8기 마지막 강의 Github, Streamlit (0) | 2023.04.26 |
| [DAY 83] Hugging Face의 transformers 사용해보기 (1) | 2023.04.24 |
| [DAY 82] 코딩테스트 연습 마지막 날 문제 풀이와 총 정리 (0) | 2023.04.21 |
| [DAY 81] Week 18 Last Insight Day 미드프로젝트2 리뷰 리포트 (0) | 2023.04.20 |




댓글