Hugging Face의 transformers 라이브러리를 사용해 봤다.
기본 제공 파이프라인 기능을 실습한 후 SKT에서 공개한 한국어 GPT-2 모델을 잠깐 다뤘다.
Hugging Face

Hugging Face는 딥러닝 모델과 자연어 처리 기술을 개발하고 공유하는 회사로, 다양한 딥러닝 프레임워크를 지원하는 라이브러리와 도구를 제공한다.
대표적인 제품으로 Transformers 라이브러리가 있다. 이는 자연어 처리 모델을 구현하고 학습시키는 데 사용되며, BERT, GPT, XLNet 등 다양한 모델을 제공한다. 이러한 모델들을 자연어 이해, 기계 번역, 질문 응답, 감정 분석 등 다양한 자연어 처리 태스크에서 좋은 성능을 보여주고 있다.
또한 Pretrained Models라는 모델 저장소를 통해 다양한 언어와 태스크에 대한 사전 학습된 모델을 제공하고 있다.
Huggind Face - Transformer 모델 실습
Transformers, What can they do? (트랜스포머로 무엇을 할 수 있나요?) 문서의 예제 코드를 Colab을 통해 실습하며 트랜스포머 모델을 사용해 무엇을 할 수 있는지 익혔다. pipeline() 함수를 사용했다. 한국어로 되어 있어서 어렵지 않았다.
from transformers import pipeline가장 먼저 transformers의 pipeline 함수를 로드한다.
허깅페이스에서 기본 제공하고 있는 pipeline 기능
1. sentiment-analysis : 감정 분석
2. zero-shot-classification : 제로샷 분류
3. text-generation : 텍스트 생성
4. fill-mask : 마스크 채우기
5. ner : 개체명 인식
6. question-answering : 질의응답
7. summarization : 요약
8. translation : 번역
총 8가지에 대해 아래에서 실습한다.
sentiment-analysis : 감정 분석
classifier = pipeline("sentiment-analysis") # 감정 분석
classifier(
["I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
"I love this pizza",
"Nice to meet you"
]
)
# 실행 결과
[{'label': 'POSITIVE', 'score': 0.9598049521446228},
{'label': 'NEGATIVE', 'score': 0.9994558691978455},
{'label': 'POSITIVE', 'score': 0.9998273253440857},
{'label': 'POSITIVE', 'score': 0.9997861981391907}]각 문장에 대해 Positive(긍정)과 Negative(부정)을 판별한다.
zero-shot-classification : 제로샷 분류
classifier = pipeline("zero-shot-classification") # 제로샷 분류
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)
# 실행 결과
{'sequence': 'This is a course about the Transformers library',
'labels': ['education', 'business', 'politics'],
'scores': [0.8445989489555359, 0.11197412759065628, 0.04342695698142052]}입력 텍스트와 후보 레이블을 인자로 전달하며 입력 텍스트와 가장 유사한 후보 레이블 확인한다.
text-generation : 텍스트 생성
generator = pipeline("text-generation") # 텍스트 생성
generator("In this course, we will teach you how to")
# 실행 결과
[{'generated_text': 'In this course, we will teach you how to design an Arduino Leonardo (and Arduino Mega) and how to run your project in a real-world scenario. We will look at how to open up a port and create the basic code. We will'}]주어진 문장 뒤에 이어질 새로운 텍스트를 생성한다.
fill-mask : 마스크 채우기
unmasker = pipeline("fill-mask") # 마스크 채우기
unmasker("I'm going to hospital and meet a <mask>.", top_k=2)
# 실행 결과
[{'score': 0.1983894556760788,
'token': 3299,
'token_str': ' doctor',
'sequence': "I'm going to hospital and meet a doctor."},
{'score': 0.128359854221344,
'token': 9008,
'token_str': ' nurse',
'sequence': "I'm going to hospital and meet a nurse."}]<mask> 토큰에 들어갈 단어를 예측하여 가장 가능성 높은 top_k개 단어를 반환한다. 병원에 가서 의사, 간호사를 만난다는 결과를 받았다.
ner : 개체명 인식
ner = pipeline("ner", grouped_entities=True) # 개체명 인식
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
# 실행 결과
[{'entity_group': 'PER',
'score': 0.9981694,
'word': 'Sylvain',
'start': 11,
'end': 18},
{'entity_group': 'ORG',
'score': 0.9796019,
'word': 'Hugging Face',
'start': 33,
'end': 45},
{'entity_group': 'LOC',
'score': 0.9932106,
'word': 'Brooklyn',
'start': 49,
'end': 57}]입력 문장에서 개체명을 인식한다. PER(사람), ORG(조직), LOC(지역)가 인식된 것을 확인할 수 있다.
question-answering : 질의응답
question_answerer = pipeline("question-answering") # 질의 응답
question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)
# 실행 결과
{'score': 0.6949767470359802, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}주어진 문맥에서 주어진 질문에 대한 답변을 반환한다.
summarization : 요약
summarizer = pipeline("summarization") # 요약
summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)
# 실행 결과
[{'summary_text': ' The number of engineering graduates in the United States has declined in recent years . China and India graduate six and eight times as many traditional engineers as the U.S. does . Rapidly developing economies such as China continue to encourage and advance the teaching of engineering . There are declining offerings in engineering subjects dealing with infrastructure, infrastructure, the environment, and related issues .'}]입력된 텍스트를 요약한 결과를 반환한다.
translation : 번역
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en") # 번역
translator("Ce cours est produit par Hugging Face.")
# 실행 결과
[{'translation_text': 'This course is produced by Hugging Face.'}]입력된 텍스트를 지정된 언어에서 다른 언어로 번역하는 작업을 수행한다. 이 예시에서는 프랑스어를 영어로 번역했다.
translator2 = pipeline("translation", model="Helsinki-NLP/opus-mt-ko-en") # 한국어 -> 영어번역
translator2("이 문장을 영어로 번역해주세요.")
# 실행 결과
[{'translation_text': 'Translate this sentence into English.'}]한국어를 영어로 번역하는 파이프라인을 생성해서 결과를 확인했다.
이후 transformers 라이브러리 GPT2LMHeadModel 클래스의 from_pretrained 함수를 통해 사전 학습된 한국어 GPT-2 모델(KoGPT2)을 불러오고 모델의 generate메소드를 이용하여 문장을 생성해 보는 실습도 진행했으나, 기대 이하의 성능을 보였다.

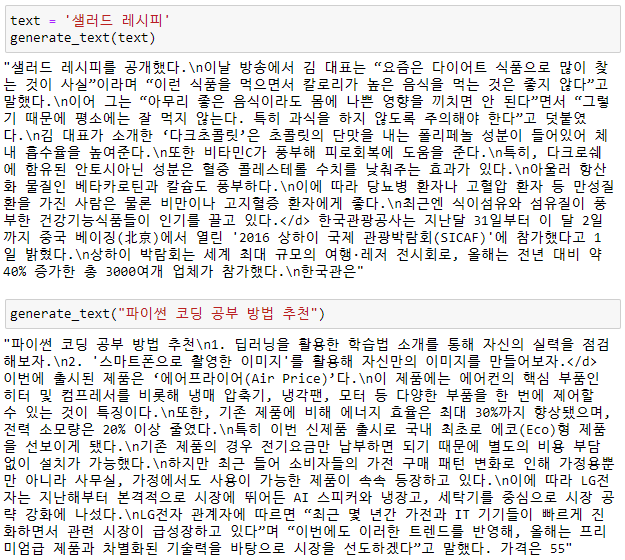
얘기만 듣던 Hugging Face와 Transformer였는데 직접 실습해 보니 재미있었다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 85] AI School 8기 마지막 강의 Github, Streamlit (0) | 2023.04.26 |
|---|---|
| [DAY 84] Content based recommendation system 콘텐츠 기반 추천 시스템 (0) | 2023.04.25 |
| [DAY 82] 코딩테스트 연습 마지막 날 문제 풀이와 총 정리 (0) | 2023.04.21 |
| [DAY 81] Week 18 Last Insight Day 미드프로젝트2 리뷰 리포트 (0) | 2023.04.20 |
| [DAY 80] Bidirectional RNN을 통해 삼성전자 주가 예측하기 (0) | 2023.04.19 |



댓글