고객의 과거 데이터를 통해 미래 가치를 추출하고 계산하며 고객을 분류할 수 있는 간단하고 유용한 방법인 RFM에 대해 공부했다.
분석 과정을 통해 데이터를 의미 있는 정보로 전환하여 마케팅에 가장 많이 사용되고 있다.
RFM
RFM은 고객의 가치를 아래 세 가지 기준에 근거해 계산한다.
1. Recency : 거래의 최근성
- 고객이 얼마나 최근에 구입했는가?
2. Frequency : 거래 빈도
- 고객이 얼마나 빈번하게 구입했는가?
3. Monetary : 거래 규모
- 고객이 구입한 총 금액은 어느 정도인가?
RFM의 개념을 익힌 후 이를 적용해 데이터를 분석했다.
데이터 준비
영국 온라인 소매점 거래 데이터셋을 이용했다.
raw = pd.read_csv('online_retail.csv')
raw.shape
# 실행 결과
(541909, 8)
541909행의 데이터 중 유효하지 않은 데이터는 사용하지 않는다.
raw_valid = raw.loc[(raw['CustomerID'].notnull()) & (raw['Quantity'] > 0) & (raw['UnitPrice'] > 0)].copy()
raw_valid고객ID가 NULL이 아니고, 수량과 가격이 0보다 큰 구매 건만 남기도록했다.
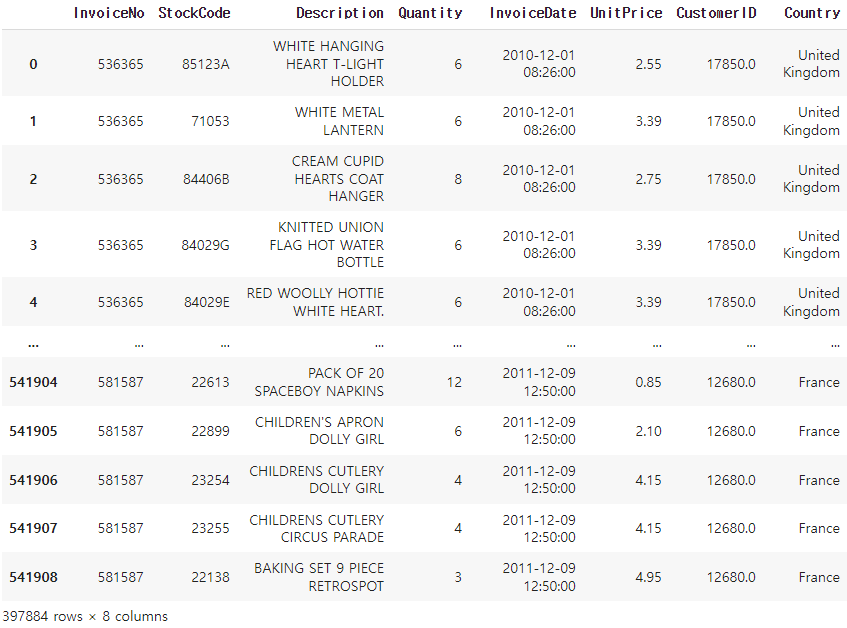
raw_valid["TotalPrice"] = raw_valid['Quantity'] * raw_valid['UnitPrice']
df = raw_valid.drop_duplicates().copy()
df거래 한 건에 대한 구매 금액 TotalPrice를 계산하고, 중복 데이터를 제거하여 df에 대입하였다.
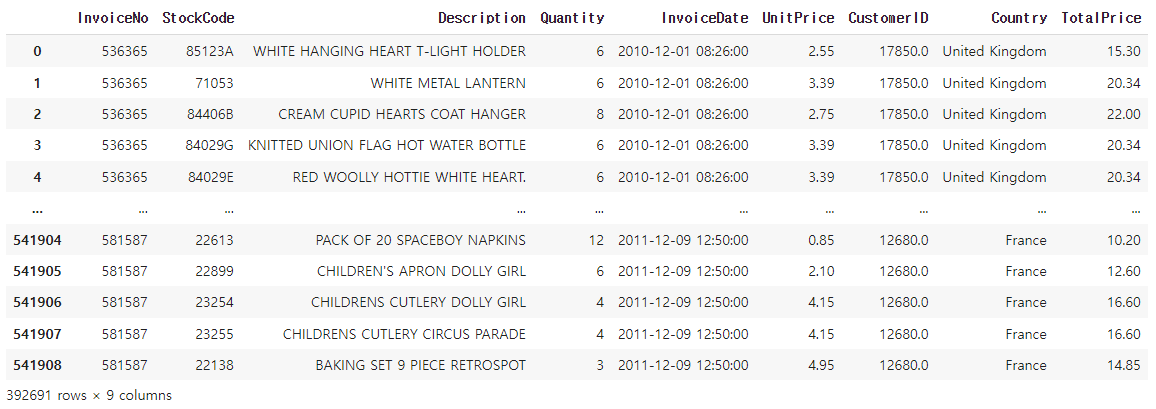
RFM을 적용하여 활용할 데이터프레임이 준비되었다.
RFM 계산
거래 데이터를 통해 CustomerID를 기준으로 groupby하여 고객별 RFM 값을 구했다.

Recency : 전체 최근 거래 기준일 - 고객별 최근 거래 날짜
Frequency : 총 구매 빈도수
MonetaryValue : 총 구매 금액
RFM 모형
RFM의 요인을 각각 등간격으로 5등분하여 분류하는 방법인 Scoring 기법을 사용한다.
pandas의 qcut을 이용하여 R, F, M 변수를 만들 것이다.
cut과 qcut의 차이는 다음과 같다.
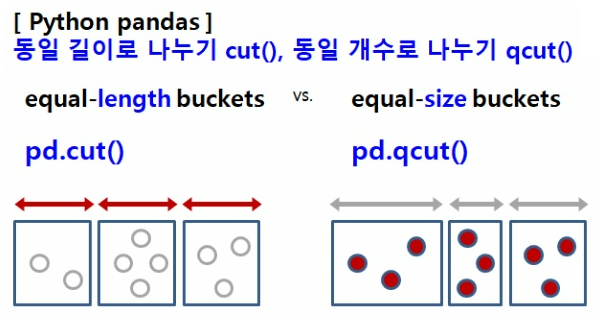
cut()은 히스토그램의 bins와 같이 같은 길이로 구간을 나눈다.
- 예시) 절대평가 - 점수로 학점을 분류
qcut()은 같은 개수로 구간을 나누며 길이가 다를 수 있다
- 예시) 상대평가 - 상위n명, 그다음n명,...으로 학점을 분류
1점이 낮게, 5점이 높은 의미로 고객의 RFM을 5구간으로 나눈다.
r_labels = list(range(5, 0, -1))
f_labels = list(range(1, 6))
m_labels = list(range(1, 6))
cut_size = 5
r_cut = pd.qcut(rfm['Recency'], cut_size, labels=r_labels)
f_cut = pd.qcut(rfm['Frequency'], cut_size, labels=f_labels)
m_cut = pd.qcut(rfm['MonetaryValue'], cut_size, labels=m_labels)
rfm = rfm.assign(R=r_cut, F=f_cut, M=m_cut)
rfm.head()Recency가 낮을수록(최근에 구매했을수록) R값이 높게, Frequency와 MonetaryValue는 높을수록(더 많은 횟수, 더 많은 금액) F, M 값이 높게 만들었다.

Recency, Frequency, MonetaryValue에 따라 R, F, M이 잘 만들어졌다.
히스토그램을 그려 보면
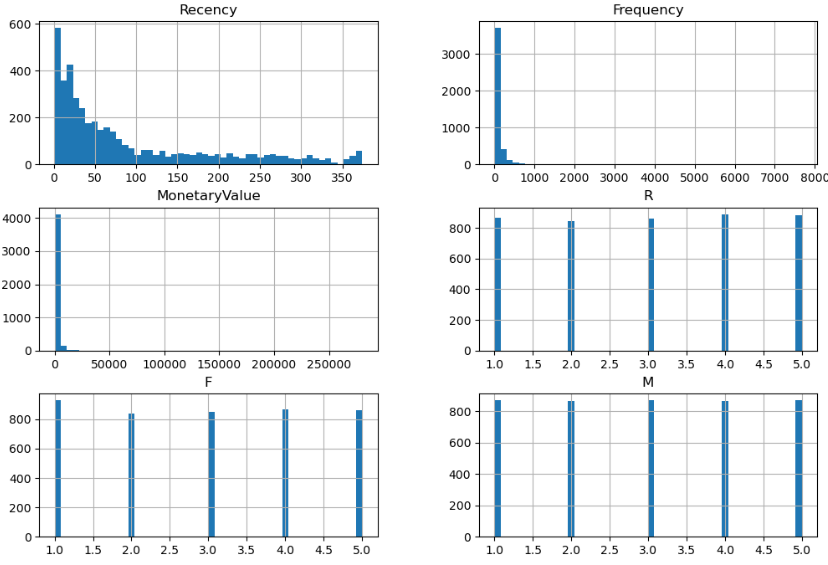
기존에 몰려있던 데이터가 구간화를 통해 균일한 분포로 나타남을 볼 수 있다.
3D 시각화 : Recency, Frequency, MonetaryValue
ax = plt.axes(projection='3d')
ax.scatter3D(rfm["Recency"], rfm["Frequency"], rfm["MonetaryValue"])
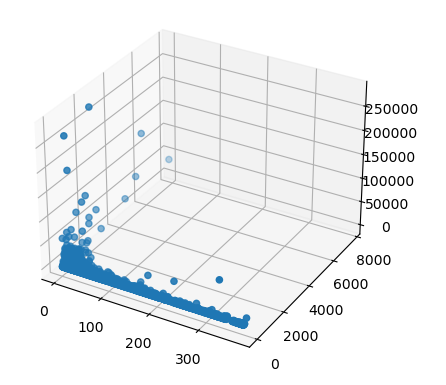
구간화 하기 전 Recency, Frequency, MonetaryValue 값에 따라서는 편향된 것을 확인할 수 있지만
3D 시각화 : R, F, M
ax = plt.axes(projection='3d')
ax.scatter3D(rfm['R'], rfm['F'], rfm['M'])

구간화 한 후엔 R, F, M 값에 편향되지 않고 균일한 분포를 확인할 수 있다.
RFM 활용
rfm["RFM_score"] = rfm[['R', 'F', 'M']].sum(axis=1)
rfm["RFM_class"] = pd.qcut(rfm['RFM_score'], 3, ['silver', 'gold', 'platinum'])고객별 R, F, M 값을 더한 RFM_score를 계산하고, 이를 다시 qcut을 이용해 3등분하여 silver, gold, platinum 등급으로 고객군을 나눈다.
rfm.groupby('RFM_class')['RFM_score'].describe()RFM_class별로 그룹핑한 후 RFM_score의 기술통계를 확인하면
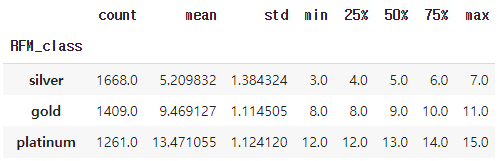
RFM_score가 3~7점이면 silver, 8~11점이면 gold, 12~15점이면 platinum으로 나누어진 것을 확인할 수 있다.
아래처럼 seaborn pointplot을 그려 각 RFM_class별로 R, F, M 값에 따라 RFM_score가 어떻게 나타나는지 확인 가능하다.
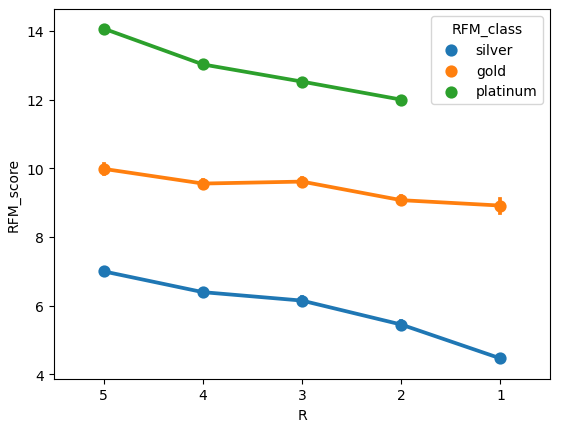
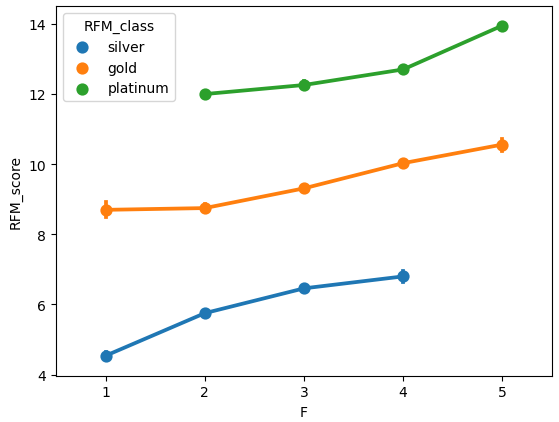
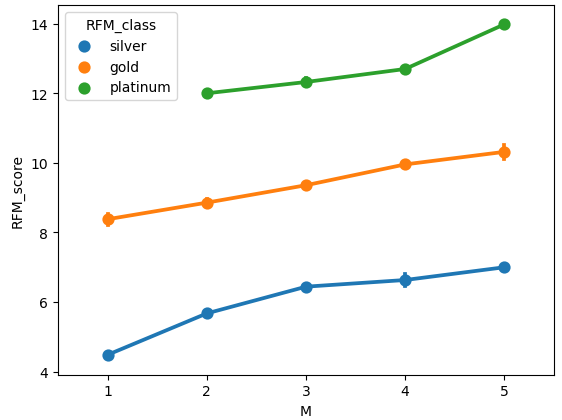
Recency, Frequency, MonetaryValue, RFM_score의 pairplot을 RFM_class별로 확인하면 아래와 같다.
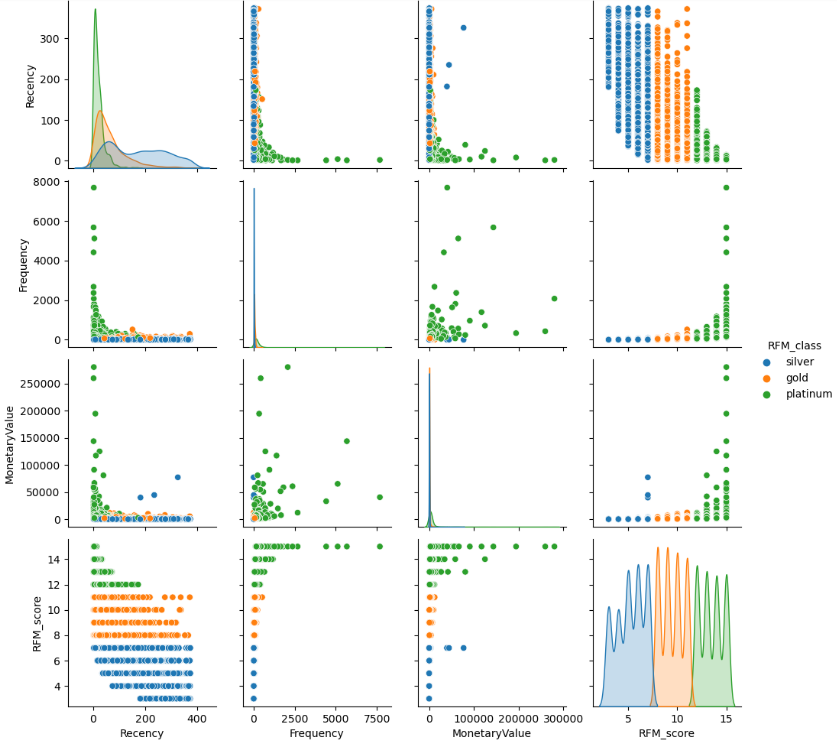
silver, gold, platinum 회원 등급별로 뚜렷한 특징의 차이를 보여준다.
어떻게 RFM 분석을 활용하는지 익혔고, 왜 마케팅에 많이 사용되는지 알 수 있었다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 50] Decision Tree를 이용한 분류, 학습과 예측, Accuracy (0) | 2023.03.08 |
|---|---|
| [DAY 49] 머신러닝, K-means clustering algorithm (0) | 2023.03.07 |
| [DAY 47] Tableau 시작 - 원본 페이지, 주요 키워드, 차트 그리기 (0) | 2023.03.04 |
| [DAY 46] Week 11 Insight Day (0) | 2023.03.02 |
| [DAY 45] Online Retail Data EDA (0) | 2023.02.28 |



댓글