머신러닝과 scikit-learn에 대해 학습하는 것으로 강의가 시작되었다.
어제 retail data를 기반으로 만든 RFM 데이터와 군집화 알고리즘 K-means를 이용하여 실습하였다.
머신러닝, scikit-learn
파이썬의 머신러닝 라이브러리 scikit-learn의 대표적 기능
1. Classification(분류)
2. Regression(회귀)
3. Clustering(군집화)
4. Dimensionality Reduction(차원 축소)
5. Model selection and evaluation(모델 선택 및 평가)
6. Preprocessing(전처리)
머신러닝, 딥러닝에서 추상화된 도구(scikit-learn, TensorFlow, pyTorch, FastAI 등)를 사용했을 때 장단점
장점
- 개발 시간 단축
- 정확성 향상(오류 감소)
- 재사용성
단점
- 일반성 부족
- 실제 동작의 이해 부족
- 구성의 어려움
- 메모리 사용량 증가
머신러닝 용어
지도학습 : 정답(label)이 있는 데이터를 학습
- 분류 : 범주형 데이터를 각 class별로 나누는 것(범주형 변수)
- 회귀 : 하나의 가설에 미치는 수치형 변수들과의 인과성 분석(수치형 변수)
비지도학습 : 정답(label)이 없는 데이터를 학습
- 군집화 : 유사도가 높은 범주끼리 모아주는 것. 분류와는 다르게 정답이 없다(범주형 변수)
- 차원 축소 : 고차원 데이터를 차원을 축소하여 분석할 특성을 줄이고 한눈에 볼 수 있게 해준다(수치형 변수)
어떤 최적화 알고리즘이든 모든 문제에서 효과적일 수 없다.
다시 말해, 최적화 문제의 성격에 따라 알고리즘의 성능이 다르게 나타난다.
따라서 최적화 알고리즘을 선택할 때는 문제의 특성과 목적에 적합한 알고리즘을 선택해야 한다.
시대에 따라서 유행이 존재하기도 한다.
K-means 알고리즘을 통한 군집화 실습
고객 4338명의 Recency, Frequency, Monetary를 계산한 데이터를 사용하였다.


Recency, Frequency, Monetary의 스케일의 차이가 있고 편차가 큰 것을 확인할 수 있다.

히스토그램으로 확인하면 편향이 직관적으로 보인다.
각각의 변수에 로그함수를 적용하여 편차를 작게 줄였다.

히스토그램으로 확인하면 편향성이 사라진 것을 확인할 수 있다. 정규분포 형태도 보인다.
이후 StandardScaler를 통해 평균이 0, 표준편차가 1이 되도록 변환하여 스케일을 조정한다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(rfm_cluster_log)
X = ss.transform(rfm_cluster_log)그리고 군집 수를 2~19개로 설정한 K-means algorithm을 적용한다.
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
inertia = []
silhouettes = []
range_n_clusters = range(2, 20)
for n_cluster in range_n_clusters:
kmeans = KMeans(n_clusters=n_cluster, random_state=42)
kmeans.fit(X)
inertia.append(kmeans.inertia_)
silhouettes.append(silhouette_score(X, labels=kmeans.labels_))
print(n_cluster, end=",")inertia는 각 군집별 오차 제곱의 합으로, 군집 내의 분산을 의미한다.
군집 수가 증가하면 inertia가 줄어들며, inertia가 빠르게 변하는 지점이 최적의 군집 수 k이다.
Elbow Method

팔꿈치처럼 급격히 꺾이는 부분이 확연히 보이진 않는다. 실제 활용에서 이런 경우가 많다고 한다.
군집 수를 3으로 지정하여 결과 확인
n_clusters = 3
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
kmeans.fit(X)
pd.Series(kmeans.labels_).value_counts()
# 실행 결과
2 1832
0 1536
1 970
dtype: int64데이터가 군집 3개로 분류되었다.
시각화해서 확인해보면

군집화된 데이터(clustered data)를 확인할 수 있다.
silver, gold, platinum으로 분류한 RFM_class와 머신러닝으로 군집화한 각 cluster를 비교해 보자.
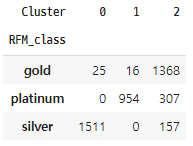
완전히 같진 않지만 어느정도 유사하게 분류된 것을 알 수 있다.
바이올린 플롯을 그려 확인하면 아래와 같다.
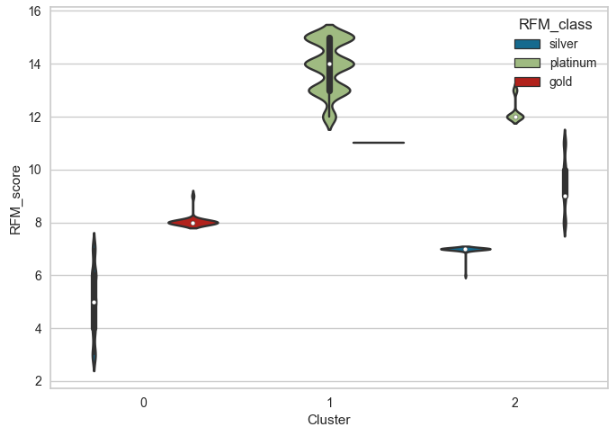
기존의 RFM_class를 구한 것처럼 qcut 방식으로 고객을 군집화 할 수 있지만 변수가 많다면 머신러닝 군집화를 사용하면 비교적 간단해질 수 있다.
K-means 군집화 알고리즘을 사용하여 머신러닝으로 고객을 군집화해 보는 시간이었다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 51] Week 12 Insight Day 미니프로젝트3 시작 (0) | 2023.03.09 |
|---|---|
| [DAY 50] Decision Tree를 이용한 분류, 학습과 예측, Accuracy (0) | 2023.03.08 |
| [DAY 48] RFM - 과거 내역을 통해 고객의 미래 가치를 추출하는 분석 방법 (0) | 2023.03.06 |
| [DAY 47] Tableau 시작 - 원본 페이지, 주요 키워드, 차트 그리기 (0) | 2023.03.04 |
| [DAY 46] Week 11 Insight Day (0) | 2023.03.02 |



댓글