영국 온라인 소매점에서 발생한 거래에 대한 데이터셋을 가지고 EDA했다.
데이터 분석 시 각각의 데이터가 어떤 것을 의미하는지 정확히 파악해야하며, 그것을 수월하게 하기 위해선 도메인 지식이 뒷받침 되어야겠다는 것을 느꼈다.
데이터 정보
online retail 데이터를 사용한다. 강사님이 로드 시간 측면에서 excel보단 csv가 유리하므로 csv를 사용하는 것을 추천하셨다. 데이터를 로드하여 변수 df에 데이터프레임으로 저장하였다.

사용할 데이터는 541909 rows, 8 columns 데이터다.
Attribute Information
- InvoiceNo : 거래에 할당된 번호, 'C'로 시작하면 취소 거래를 나타낸다.
- StockCode : 제품 코드, 각 제품에 고유하게 할당
- Description : 제품 이름
- Quantity : 거래당 각 제품의 수량, '-'(마이너스)로 시작하면 취소를 나타낸다.
- InvoiceDate : 각 거래가 생성된 날짜 및 시간
- UnitPrice : 단가(제품 가격)
- CustomerID : 고객에게 고유하게 할당된 고객 번호
- Country : 해당 고객이 거주하는 국가명
df.describe()를 통해 수치형, 범주형 기술통계를 구해보니 아래와 같았다.

Quantity와 UnitPrice의 최솟값이 음수 값이 나왔다. 취소 거래가 있기 때문이다.

unique한 주문은 25900개이며, 상품 수가 많은 주문은 573585번이다. 해당 주문에 1114개의 상품을 주문했다는 것을 알 수 있다.
결측치
df.isna().sum()과 df.isna().mean()을 이용하여 컬럼별 결측치 합계, 결측치 비율을 구했다.
Description 컬럼에 1454개(0.26%), CustomerID 컬럼에 135080개(24.92%)의 결측치가 존재하는 것을 확인했다.
이를 seaborn heatmap으로 시각화하여 확인하였다.

CustomerID가 결측치인 것은 비회원 구매인 것으로 추정할 수 있다.
하지만 현업이거나 중요한 데이터를 분석한다면 정확히 확인할 필요가 있다.
데이터 분석
Quantity(수량) * UnitPrice(금액)으로 TotalPrice(전체 금액)을 계산한 파생변수를 만들었다.
df["TotalPrice"] = df['Quantity'] * df['UnitPrice']
df.head(2)

회원 구매 vs 비회원 구매
# CustomerID값이 결측치인 경우의 Country 빈도수
df.loc[df['CustomerID'].isna(), 'Country'].value_counts()
# CustomerID값이 결측치가 아닌 경우의 Country 빈도수
df.loc[~df['CustomerID'].isna(), 'Country'].value_counts()loc, isna(), values_counts()를 통해 빈도수를 계산해본 결과 영국 거래 데이터다 보니 거의 모든 경우가 United Kingdom이었다.
매출액 상위 top 10 국가
df.groupby("Country")["TotalPrice"].agg(["mean", "sum"]).nlargest(10, "sum").style.format("{:,.0f}")groupby를 통해 국가별 TotalPrice mean과 sum을 구한 후, nlargest를 통해 매출액 합계 상위 10개국을 추출했다.

영국의 매출 합계가 압도적으로 높았다.
nlargest는 sort_values + head의 개념으로, 특정 컬럼 기준 상위 n개의 행을 추출할 수 있다.
판매 빈도 상위 top 10 상품
stock_sale = df.groupby(["StockCode"]).agg({"InvoiceNo": "count",
"Quantity": "sum",
"TotalPrice": "sum"
}).nlargest(10, "InvoiceNo")상품 코드별 상품 판매 빈도, 판매 수량 합계, 매출액 합계를 구하고 stock_sale에 저장한다.

이 상위 판매 상품 코드를 사용하여 df에서 Description을 가져와 컬럼을 추가한다.
stock_desc = df.loc[df["StockCode"].isin(stock_sale.index), ["StockCode", "Description"]]
stock_desc = stock_desc.drop_duplicates("StockCode").set_index("StockCode")
stock_sale["Desc"] = stock_desc
stock_sale그 결과 top10 상품에 대해 상품코드를 인덱스로 한 상품 판매 빈도, 판매 수량 합계, 매출액 합계와 상품 이름을 하나의 데이터프레임으로 만들었다.

구매 취소를 많이 한 고객 top 10
df["Cancel"] = df["Quantity"] < 0
df.groupby('CustomerID')['Cancel'].value_counts().unstack().nlargest(10, True)구매 취소를 True, 취소가 아닌 경우를 False로 하는 Cancel 컬럼을 추가한 후 이를 활용하여 구매 취소 수 상위 10명의 고객을 조회했다.

12607번 고객은 101회 주문하고 101회 취소하였다.!!
응용하여 구매 수 대비 취소 수를 구한 후 너무 잦은 취소를 하는 고객을 추출할 수도 있겠다.
거래 상위 10위 제품의 구매 취소 비율
cancel_stock = df.groupby(["StockCode"]).agg({"InvoiceNo":"count", "Cancel": "mean"})
cancel_stock.nlargest(10, "InvoiceNo")제품코드별 거래 수와 취소 비율을 구한 후, 거래 수 기준 상위 10위의 제품을 추출했다.
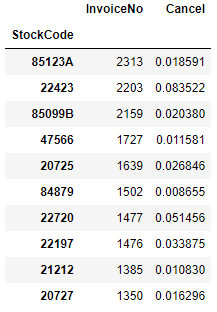
거래 수가 많은 제품 top 10의 거래 수와 취소 비율을 확인했다.
거래 상위 10위 국가의 구매 취소 비율
cancel_country = df.groupby('Country').agg({"InvoiceNo":"count", "Cancel": "mean"})
cancel_country.nlargest(10, "InvoiceNo")국가별 거래 수와 취소 비율을 구한 후, 거래 수 기준 상위 10위 국가를 추출했다.
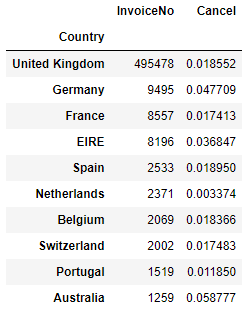
거래 수가 많은 나라 top 10의 거래 수와 취소 비율을 알 수 있다.
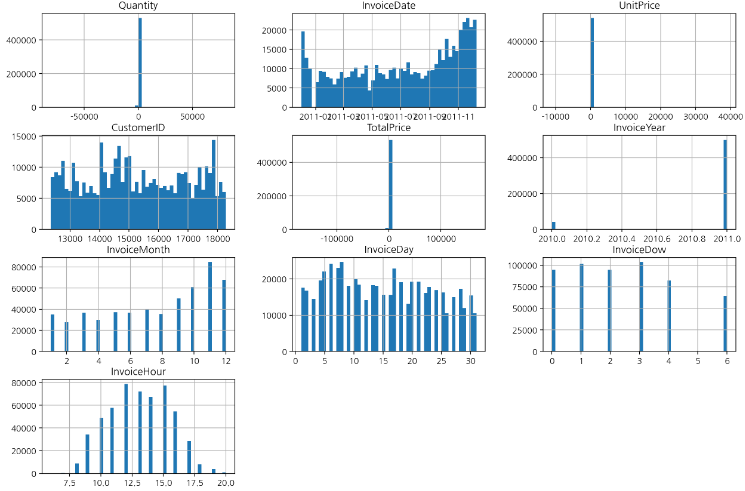
날짜와 시간 다루기
df의 InvoiceDate 컬럼을 datetime 형식으로 변환한 후 dt accessor를 이용하여 연, 월, 일, 요일, 연월, 시간에 대한 파생 변수를 생성했다.
그 후 df.hist()로 전체 수치 변수의 histogram을 그려 확인했다.
연도별 구매 빈도수
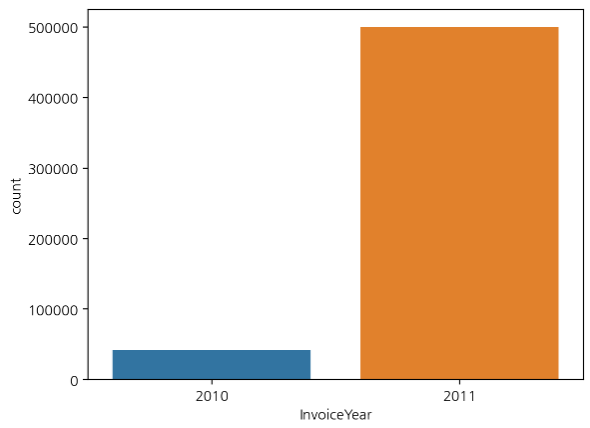
InvoiceYear(연도) 파생 변수 기준 거래 빈도수를 seaborn countplot으로 그렸다.
스토어가 1년 사이에 엄청난 성장을 이룬 것일까? 그건 아니다. 아래 그래프를 보자.
연도-월별 구매 빈도수
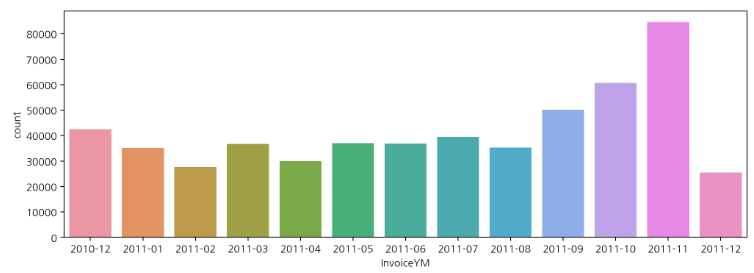
InvoiceYM(연도-월)을 기준으로 보면 데이터의 시작점이 2010년 12월이다.
2010년과 2011년의 거래 수가 많이 차이났던 이유를 알 수 있다. 2010년의 데이터는 12월밖에 없었기 때문이다.
요일별 구매 빈도수
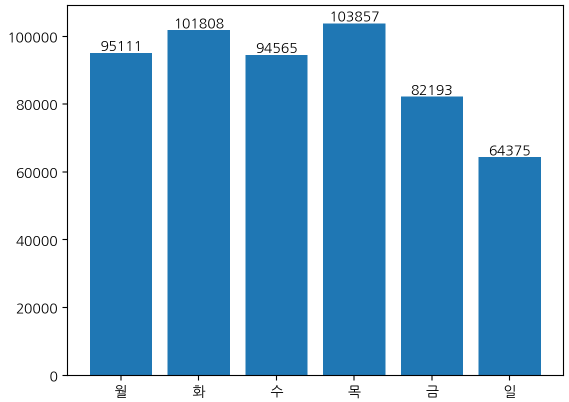
요일별 구매 빈도수를 수치가 표시된 막대그래프로 나타냈다.
일요일이 유의미하게 빈도수가 적은 것을 확인할 수 있다.
시간대별 구매 빈도수
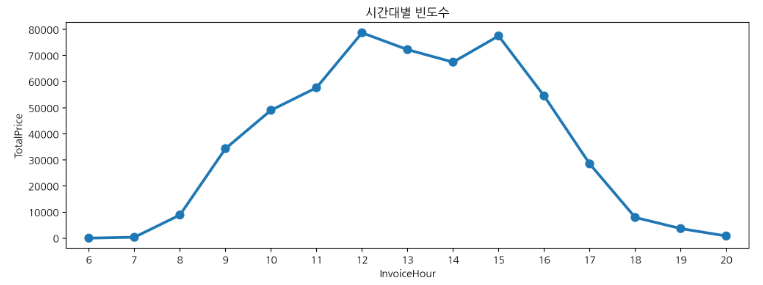
시간대별 구매 빈도수를 seaborn pointplot으로 그렸다. 12~15시경에 구매가 많이 발생한 것을 확인할 수 있다.
시간별, 요일별 빈도수
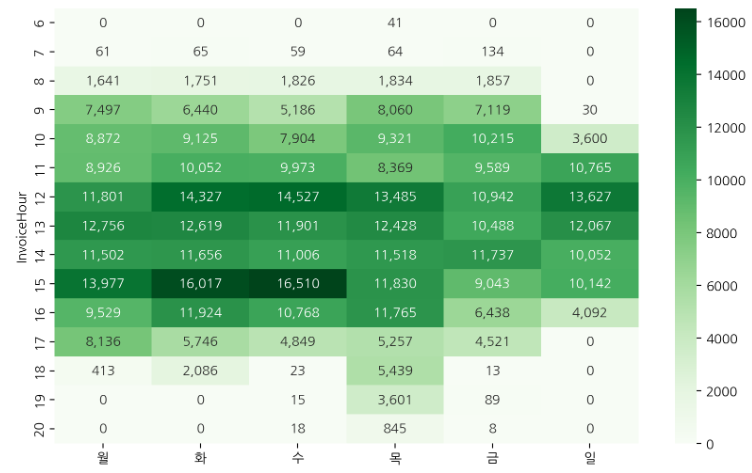
시간, 요일별 빈도수를 heatmap으로 시각화하여 어떤 요일, 어떤 시간에 주문이 집중되는지 시각적으로 확인한다.
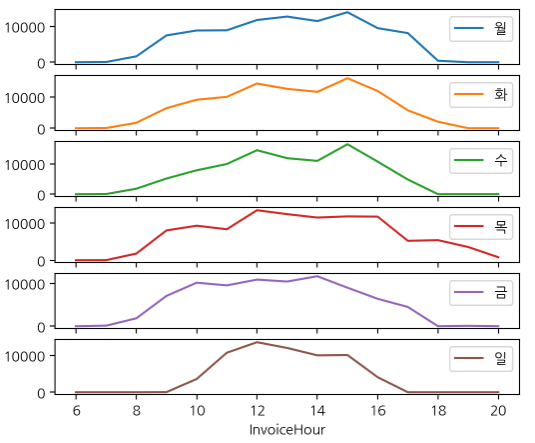
subplot을 사용하여 요일별로 비교해볼 수도 있다.
이커머스 데이터 분석을 해봤는데, 평소 '이런 식으로 하면 되지 않을까?' 생각했던 부분을 실제로 하니 재미있었다. 이커머스 데이터 분석은 다양한 도메인에서 활용이 될 것 같은데, 도메인 지식을 바탕으로 데이터를 정확히 이해할 필요성이 있겠다고 생각했다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 47] Tableau 시작 - 원본 페이지, 주요 키워드, 차트 그리기 (0) | 2023.03.04 |
|---|---|
| [DAY 46] Week 11 Insight Day (0) | 2023.03.02 |
| [DAY 44] 스토리지, 메모리 사용량 관리 parquet, downcast (0) | 2023.02.27 |
| [DAY 43] 미드프로젝트1 마무리 (0) | 2023.02.26 |
| [DAY 42] 미드프로젝트1 - 커피지수 계산식 확정, 100만 행이 넘는 데이터, 본격적인 분석과 시각화 (0) | 2023.02.23 |



댓글