머신러닝과 딥러닝의 차이를 시작으로 딥러닝에 대한 학습이 시작됐다.
활성화함수, 기울기 소실, 옵티마이저 등 어려운 개념이 많이 나왔다.
딥러닝
머신러닝과 딥러닝의 차이는 인간 개입 여부에 있다.

피처 추출을 인간이 직접 하는 머신러닝과 달리 딥러닝은 인공지능 알고리즘 내부에서 피처 추출이 이루어진다. 사람 같지만 더욱 빠른 속도를 낸다.
초기의 인공 신경망(Artificial Neural Network, ANN)은 퍼셉트론(Perceptron)이다. 1957년에 고안되었으며 가장 간단한 형태의 순방향 신경망 선형 분류기로도 볼 수 있다.
그러나 ANN은 학습 데이터에 따른 과적합 문제가 있다. 학습 데이터에만 특화된 학습이 이루어져 새로운 데이터에 대한 성능이 떨어지는 현상이다. 또한 학습 시간이 너무 느리다. 이 두 문제점은 각각 사전 훈련과 그래픽 카드 발전으로 개선되고 있다.
ANN은 다수의 입력 데이터를 받는 입력층(Input Layer), 데이터의 출력을 담당하는 출력층(Output Layer), 그 사이에 존재하는 은닉층(Hidden Layer)들로 구성된다. 모델은 은닉층의 개수와 노드의 개수를 구성하며, 모델을 잘 구성하여 원하는 Output 값을 얻는 것(잘 예측하는 것)이 해야 할 과제다.
활성화 함수(Activation Function)
인공 신경망 내부에서 입력받은 데이터를 근거로 다음 계층으로 출력할 값을 결정하는 기능을 수행한다.
신경망을 구성할 때 설정하며 각각의 레이어를 정의할 때 세부적인 함수를 선택한다. 신경망에 비선형성을 더해주는 것이다. 종류에 따라 기울기 소실 문제가 발생할 수 있다.
- sigmoid : 0~1 사이의 값. 기울기 소실 문제 존재
- ReLU : 기울기 소실 문제를 개선
- LeakyReLU : 기울기 소실 문제를 해결. ReLU 변형 형태
- tanh : 하이퍼볼릭 탄젠트. sigmoid에 비해 빠르다
기울기 소실(Gradient Vanishing)
인공 신경망에서 가중치를 업데이트하는 과정에서 뒤로 갈수록 가중치가 잘 업데이트되지 않는 현상
가중치에 따른 결과값의 기울기가 0이 되어 버려서 경사 하강법을 이용할 수 없게 되는 문제.
손실 함수(Loss Function)
실제값과 예측값의 차이를 수치화해주는 함수 : 오차가 작다 == 손실 함수값이 작다
딥러닝은 오차를 최소화하는 가중치(weight)와 편향(bias)의 조합을 찾는다.
손실함수 종류
- 분류 : BinaryCrossentropy(이항분류), CategoricalCrossentropy(다항분류) 등
- 회귀 : CosineSimilarity, MeanAbsoluteError 등
최적화함수(Optimizer)
손실 함수를 최소화하는 방향으로 가중치를 갱신, 모델이 업데이트되는 방식. 손실함수의 현 위치에서 조금씩 손실이 낮아지는 쪽으로 가중치를 움직이며 최솟값을 찾는 방법인 경사하강법에 기반을 둔다.
- SGD, RMSProp, Adam 등
실습
Tensorflow의 Keras를 이용하여 실습했다. 딥러닝 모델을 빌드하고 학습시키기 위한 간단하고 사용자 친화적인 API다. scikit-learn과 유사하다. 아래 실습을 하기 전, Tensorflow 공식 문서에서 손글씨 이미지 분류 튜토리얼과 의류 이미지 분류 튜토리얼을 선행했다.
데이터 준비
kaggle의 Telco Customer Churn 데이터를 활용했다.

데이터를 로드하여 df 변수에 담았다. 이후 결측치를 제거했다.
label_name = 'Churn'
X = pd.get_dummies(df.drop(columns=label_name))
# Yes, No -> 1, 0
y = (df[label_name] == 'Yes').astype(float)
X.shape, y.shape
# 실행 결과
((7032, 45), (7032,))원핫인코딩 후 X 데이터셋에, 타깃은 1, 0의 형태로 y에 할당했다.
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
stratify=y,
random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shapetrain_test_split을 사용해서 X_train, X_test, y_train, y_test를 생성했다.
Activation Function 시각화
import tensorflow as tf학습을 위한 tensorflow를 alias tf로 임포트
x = np.arange(-10, 10, 0.1)
plt.plot(x, x, linestyle='--')활성화함수를 적용해볼 값 생성 후 시각화
위 값에 활성화함수 sigmoid, tanh, swish, relu를 적용해본다.
plt.plot(x, tf.keras.activations.sigmoid(x), ls='--')
plt.title('sigmoid')
plt.axvline(0, alpha=0.2)
plt.axhline(0.5, alpha=0.2)
plt.show()sigmoid 적용 결과

plt.plot(x, tf.keras.activations.tanh(x), ls='--')
plt.title('tanh')
plt.axvline(0, alpha=0.2)
plt.axhline(0, alpha=0.2)
plt.show()tanh(hyperbolic tangent) 적용 결과

plt.plot(x, tf.keras.activations.swish(x), ls='--')
plt.title('swish')
plt.axvline(0, alpha=0.2)
plt.axhline(0, alpha=0.2)
plt.show()swish(SiLU) 적용 결과

sigmoid 함수에 입력값을 한 번 더 곱해준 형태
plt.plot(x, tf.keras.activations.relu(x), ls='--')
plt.title('relu')
plt.axvline(0, alpha=0.2)
plt.axhline(0, alpha=0.2)
plt.show()ReLU(Rectified Linear Unit) 적용 결과

이렇게 4개의 활성화 함수를 시각화하여 확인했다. x축은 원래의 값, y축은 활성화함수를 통과시킨 값이다.
딥러닝 레이어 만들기
input_shape = X_train.shape[1]
input_shape
# 실행 결과
45먼저 입력 데이터 수 (feature 수)를 저장했다.
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu',
input_shape=[input_shape]),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()tf.keras.Sequential로 입력층 - 은닉층 - 출력층 레이어를 구성했다.

모델 컴파일
모델 학습 전 몇 가지 설정이 컴파일 단계에서 이루어진다.
- 옵티마이저(Optimizer) : 데이터와 손실 함수를 바탕으로 모델의 업데이트 방법 결정
- 평가 지표(Metrics) : 학습, 테스트 단계를 모니터링
- 손실 함수(Loss function) : 학습하는 동안 모델의 오차 측정. 올바른 방향으로 향하도록 이 함수를 최소화해야 한다.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=optimizer,
loss='binary_crossentropy', # 바이너리 분류
metrics=['accuracy']
)Churn은 1과 0 => 이진 분류이므로 binary_crossentropy를 지정했다.
모델 학습
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=50)
history = model.fit(X_train, y_train, validation_split=0.2,
epochs=1000, callbacks=[early_stop], verbose=0)
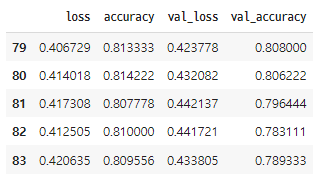
df_hist = pd.DataFrame(history.history)
df_hist.tail()validation을 20%로, val_loss 기준으로 값이 50회 이상 개선되지 않으면 early stop을 하도록 지정하여 학습했다. 전체 학습 횟수를 뜻하는 epochs는 1000을 지정했다. 아래는 학습 결과를 데이터프레임으로 반환하여 tail을 확인한 것이다.
학습 결과 시각화
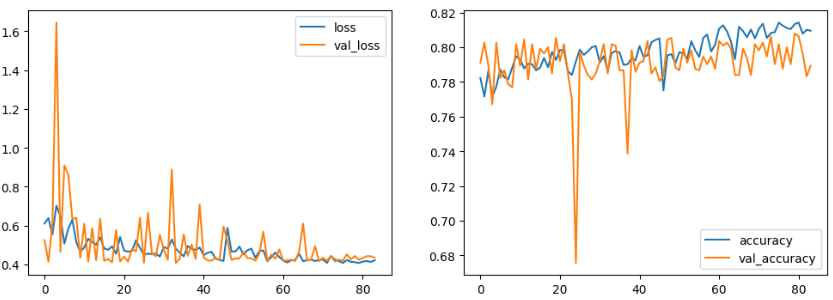
loss는 점점 감소하며 accuracy는 점점 증가하는 형태를 확인할 수 있다.
평가
test_loss, test_acc = model.evaluate(X_test, y_test)
test_loss, test_acc
# 실행 결과
(0.4510655105113983, 0.778251588344574)모델의 evaluate를 통해 평가한다. loss는 0에 가까울수록, accuracy는 1에 가까울수록 좋은 값이다.
딥러닝에 입문했다. 머신러닝과 다른 것 같으면서도 유사한 느낌이 든다. 특히 레이어 구성, 컴파일 부분이 크게 다른데, 이 부분만 잘 이해한다면 괜찮을 것 같다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 75] PyTorch를 활용한 자동차 연비 회귀 예측 (0) | 2023.04.12 |
|---|---|
| [DAY 74] Tensorflow를 활용한 자동차 연비 회귀 예측 (0) | 2023.04.11 |
| [DAY 72] 코딩테스트 연습 - Binary Search Tree, DFS, BFS, Sorting algorithms (0) | 2023.04.07 |
| [DAY 71] 미드프로젝트2 발표와 피드백, 종합 회고 (0) | 2023.04.06 |
| [DAY 70] 미드프로젝트2 마무리 (0) | 2023.04.05 |



댓글