Special Lecture 코딩테스트 연습의 첫 번째 시간이었다.
코테 준비사항과 문제 유형 등에 대한 안내를 받고, 시간복잡도의 개념과 파이썬 리스트를 이용한 자료구조를 다루었다.
코테 준비사항, 문제 유형
준비사항
- 플랫폼에 익숙해지자
- 코드 스니펫 만드는 것을 추천
- 유용한 라이브러리 정리
- 예외처리에 유의
- 속도를 개선하자
- class 활용, 메소드 대신 슬라이싱, for loop 대신 list comprehension 등
문제 유형
알고리즘
- 정렬
- 이진 검색
- 비트 연산
- 슬라이딩 윈도우, 페이지 교체
- 분할 정복
- 그리디 알고리즘
- 다이나믹 프로그래밍
자료구조
- 선형 : 스택, 큐, 데크, 연결리스트, 해시테이블 등
- 비선형 : 그래프(최단 경로), 트리, 힙 등
알고리즘 측정의 대표적 방법
시간복잡도(Time Complexity) : 얼마나 많은 시간이 걸리는가
- 연산 횟수가 다항식으로 표현될 경우 상수는 무시하고 최고차항의 차수로만 표현
- Worst Case : Big-O notation
- ex) N^2 + 3N + 4 => O(N)
- N 값이 커지면 커질수록 시간복잡도가 큰 알고리즘은 수행시간이 급격하게 길어진다.
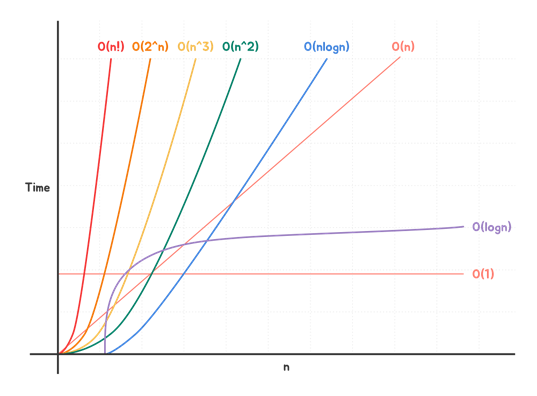
=> 시간복잡도가 낮은 알고리즘을 작성하자
공간복잡도(Space Complexity) : 얼마나 많은 공간을 사용하는가
- 알고리즘이 수행되는데 필요한 메모리의 총량
- 최근에는 메모리의 발전으로 시간 복잡도에 비해 중요도가 낮아짐
워밍업
1. 1부터 10000까지 자연수 중 숫자 8이 나오는 횟수 카운트
- 8이 포함된 숫자의 갯수가 아닌, 8을 모두 센다. 예시 : 1808은 2회
total = 0
for i in range(1, 10001):
total += str(i).count('8')
print(total)
# 실행 결과
4000첫 번째 풀이는 for loop를 이용한 풀이다.
반복문을 돌며 숫자를 문자열로 바꿔준 후 count('8')을 하므로 속도가 느리다.
str(list(range(1, 10001))).count('8')
# 실행 결과
4000효율적인 풀이는 위와 같다.
1~10000 range를 리스트로 바꾸고 한 번에 문자열로 바꾼 후 count를 한 번 사용한다.
sorted, lambda
l = [
[6, 'a', 'hello'],
[3, 'f', 'hello world'],
[7, 'b', 'hello a'],
[8, 'g', 'hello world hello'],
[4, 'e', 'hello aa'],
[2, 'c', 'hello world hello world'],
[1, 'd', 'hello abc'],
]위 리스트를 여러 기준으로 정렬해보자.
# 알파벳 순서로 정렬
sorted(l, key=lambda x: x[1])
# 실행 결과
[[6, 'a', 'hello'],
[7, 'b', 'hello a'],
[2, 'c', 'hello world hello world'],
[1, 'd', 'hello abc'],
[4, 'e', 'hello aa'],
[3, 'f', 'hello world'],
[8, 'g', 'hello world hello']]각 element list의 index 1 기준으로(알파벳 순서) 정렬되었다.
# 문자열 길이 순서로 정렬
sorted(l, key=lambda x: len(x[2]))
# 실행 결과
[[6, 'a', 'hello'],
[7, 'b', 'hello a'],
[4, 'e', 'hello aa'],
[1, 'd', 'hello abc'],
[3, 'f', 'hello world'],
[8, 'g', 'hello world hello'],
[2, 'c', 'hello world hello world']]각 element list의 index 2 길이 기준으로(문자열 길이 기준) 정렬되었다.
l = [-1, 10, -5, 3, 7, -8, 5, 4]
sorted(l, key=lambda x: x**2, reverse=True)
# 실행 결과
[10, -8, 7, -5, 5, 4, 3, -1]위 코드는 어떤 방식으로 정렬한 것일까?
각 원소의 제곱 크기 기준으로 정렬했으며, reverse=True를 사용해서 제곱값이 큰 순으로 정렬되었다.
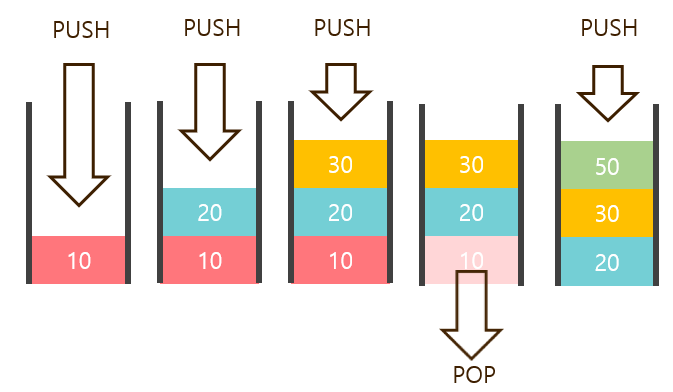
Stack, Queue
Stack(스택), Queue(큐)는 프로그래밍 언어가 생겨날 때부터 있던 고전적 개념이다.
Stack은 LIFO(Last In First Out, 후입선출) 방식, Queue는 FIFO(First In First Out, 선입선출) 방식으로 동작한다.
각각 DFS(Depth First Search, 깊이 우선 탐색), BFS(Breadth First Search, 너비 우선 탐색)에 사용된다.
파이썬 class와 list를 이용하여 스택과 큐를 구현해보자.
# 스택 구현
class Stack:
def __init__(self):
print('Stack이 만들어 졌습니다!')
self.l = []
def push(self, data):
self.l.append(data)
def pop(self):
return self.l.pop()
def top(self):
return self.l[-1]
def bottom(self):
return self.l[0]
def empty(self):
return self.l간단하게 구현했다. 아래에서 동작을 확인하자.
s = Stack()Stack 객체가 생성되며 Stack이 만들어 졌습니다!를 출력한다.
s.push(10)
s.push(20)
s.push(30)
s.l
# 실행 결과
[10, 20, 30]10, 20, 30을 차례로 push하고
s.pop()
s.push(50)
s.l
# 실행 결과
[10, 20, 50]pop을 하면 마지막으로 push한 30이 제거된다(LIFO). 그리고 다시 50을 push한 후 확인한 결과다.

s.top(), s.bottom()
# 실행 결과
(50, 10)스택의 최상단에는 50, 최하단에는 10이 저장된 형태인 것을 알 수 있다.
이번에는 큐를 구현했다.
# 큐 구현
class Queue:
def __init__(self):
print('Queue 생성됨')
self.l = []
def push(self, data):
self.l.append(data)
def pop(self):
return self.l.pop(0)생성자와 push, pop만 간단히 구현했다.
q = Queue()
q.push(10)
q.push(20)
q.push(30)
q.push(40)
q.l
# 실행 결과
Queue 생성됨
[10, 20, 30]스택과 마찬가지로 객체를 생성하고 10, 20, 30을 차례로 push했다.
q.pop()
q.push(50)
q.l
# 실행 결과
[20, 30, 50]여기서 스택과의 차이점을 확인할 수 있다. 큐는 pop 결과 제일 처음 push한 10이 제거되었다.(FIFO)
연결리스트
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
init = Node('init')
self.head = init
self.tail = init
self.node_count = 0
def __len__(self):
return self.node_count
def __str__(self):
current = self.head
current = current.next
s = '' # <12, 99, 37, 2> 형태로 만들자
for i in range(self.node_count):
s += f'{current.data}, '
current = current.next
return f'<{s[:-2]}>'
def append(self, data):
new_node = Node(data)
self.tail.next = new_node
self.tail = new_node
self.node_count += 1
def pop(self):
last = self.tail.data
current = self.head
for i in range(self.node_count):
if current.next is self.tail:
self.tail = current
current.next = None
break
current = current.next
self.node_count -= 1
return last
def find(self, data):
index = -1
current = self.head
for i in range(self.node_count + 1): # init 데이터가 있기 때문에 +1
if current.data == data:
return index
index += 1
current = current.next
return -1클래스를 사용하여 Singly Linked List를 구현했다. append 메소드를 통해 노드를 생성하고 자동으로 연결하는 방식이다.
l = LinkedList()
l.append(12)
l.append(99)
l.append(37)
l.append(2)
l.head.data
# 실행 결과
'init'연결리스트를 만들 때 첫 노드는 head가 되고 데이터는 'init'이다. 12, 99, 37, 2를 연결해 주었다.
연결한 리스트의 값을 확인하려면 아래와 같이 하면 된다.
l.head.next.data # 12
l.head.next.next.data # 99
l.head.next.next.next.data # 37연결된 관계를 생각하며 이해해야한다.
len(l)
# 실행 결과
4매직메소드를 통해 현재 추가된 노드의 개수를 출력할 수 있으며
print(l)
# 실행 결과
<12, 99, 37, 2>연결된 노드의 데이터를 확인할 수 있다.
l.find(99), l.find(37)find()를 사용하면 해당 데이터가 몇 번째 노드에 있는지를 반환한다.
데이터 분석과 시각화, 머신러닝에 집중하다 보니 파이썬 알고리즘 공부는 오랜만이었는데 재미있었다.
앞으로 3회차가 남았으니 집중해서 많은 것을 흡수해야겠다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 69] 미드프로젝트2 - 프로젝트 멘토 피드백, 머신러닝 (0) | 2023.04.04 |
|---|---|
| [DAY 68] 미드프로젝트2 데이터 준비, EDA (0) | 2023.04.03 |
| [DAY 66] Week 15 Insight Day 미드프로젝트2 시작 (0) | 2023.03.30 |
| [DAY 65] Numpy를 이용한 SVD(특이값 분해) (0) | 2023.03.30 |
| [DAY 64] 뉴스 토픽 분류 - KoNLpy, 어간 추출, 불용어 제거, TfidfVectorizer (0) | 2023.03.28 |



댓글