자연어 처리(Natural Language Processing, NLP)에 대해 배웠다.
자연어처리의 의미와 활용성, 관련 용어를 익히고 scikit-learn을 이용해 실습했다.
자연어 처리(Natural Language Processing, NLP)
자연어와 자연어 처리
자연어란 인간이 일상생활에서 사용하는 언어로, 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 것이 자연어 처리다. 기계에게 인간의 언어를 이해시키는 인공지능의 분야 중 하나
자연어 처리로 할 수 있는 일
음성 인식, 내용 요약, 번역 등
감정 분석(긍정/부정 등)
텍스트 분류(스팸 메일 분류, 뉴스 기사 카테고리 분류 등)
질의응답 시스템, 챗봇 등
자연어 분류 과정
데이터 로드(텍스트 데이터) -> 데이터 전처리 -> 데이터 분할 -> 데이터 벡터화
코퍼스(Corpus)
언어 연구를 위해 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 자료
매체, 시간, 공간, 주석 단계 등의 기준에 따라 다양한 종류가 있다.
토큰화
주어진 Corpus에서 텍스트를 토큰(token)이라 불리는 단위로 나누는 작업
특정 문자로 텍스트 데이터를 나눈다.
대표적 토큰화 패키지로 nltk가 있지만 한국어를 지원하지 않는다.
불용어(Stopword)
문장에서 자주 등장하지만 실제 의미 분석을 하는 데 도움이 되지 않는 조사, 접미사 같은 단어
영어에서는 불용어 사전을 사용하지만 한국어의 경우 주제나 프로젝트에 맞게 만들어 사용
유의미한 단어 토큰만을 선별하기 위해서는 큰 의미가 없는 단어 토큰을 제거하는 작업 필요
- 예시) 조사, 접미사, 나, 너, 은, 는, 이, 가, 하다, 합니다 등
BoW(Bag of Words)
텍스트를 담는 가방. 단어들의 출현 빈도(frequncy)에만 집중하는 텍스트 데이터의 수치화 표현 방법
매우 간단하며 텍스트 분석에서 널리 쓰이는 방법 중 하나
문맥과 관련된 정보를 무시하고 각 단어를 독립적 단위로 취급하기 때문에 단어의 순서가 무시되는 단점이 있다.
예시 ) It's bad, not good at all / It's good, not bad at all
-> BoW : ["It's", "not", "at", "all", "bad", "good"]
=> 예시의 두 문장은 완전히 반대의 의미를 가지지만 BoW로 토큰화하면 동일화된다
DTM(Document-Term Matrix, 문서 단어 행렬)
다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것
즉, 각 문서에 대한 BoW를 하나의 행렬로 만든 것
TF(Term Frequency, 단어 빈도)
특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값
이 값이 높을수록 문서에서 중요하다고 생각할 수 있지만 단어 자체가 문서군 내에서 자주 사용되는 경우에는 그 단어가 흔하게 등장한다는 의미
TF-IDF(Term Frequency-Inverse Document Frequency, 단어 빈도-역 문서 빈도)
여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치
문서의 핵심어를 추출하거나, 검색 엔진에서 검색 결과의 순위를 결정하거나, 문서들 사이의 비슷한 정도를 구하는 등의 용도로 사용할 수 있다.
사이킷런은 TF-IDF를 자동 계산해 주는 TfidfVectorizef를 제공

CountVectorizer
사이킷런에서 제공하는 bag of words를 만들 수 있는 방법
텍스트 문서 모음을 토큰 수의 행렬로 변환
단어들의 count(출현 빈도)로 여러 문서를 벡터화
문서 목록에서 각 문서의 feature(문장 특징) 노출 수를 가중치로 설정한 BoW 벡터 생성
TfidfVectorizer
TF-IDF를 계산하는 사이킷런의 함수
단어 개수 그대로 카운트하지 않고 모든 문서에 공통적으로 들어 있는 단어는 낮은 구별력을 가진 단어로 판단, 가중치를 축소
자연어 처리 실습
corpus = ["코로나 거리두기와 코로나 상생지원금 문의입니다.",
"지하철 운행시간과 지하철 요금 문의입니다.",
"지하철 승강장 문의입니다.",
"코로나 선별진료소 문의입니다.",
"버스 운행시간 문의입니다.",
"버스 터미널 위치 안내입니다.",
"코로나 거리두기 안내입니다.",
"택시 승강장 문의입니다."
]분석할 문서는 8개로 구성된다.
from sklearn.feature_extraction.text import CountVectorizer
cvect = CountVectorizer()sklearn 라이브러리에서 제공하는 BoW를 만들 수 있는 CountVectorizer 객체를 생성했다.
dtm = cvect.fit_transform(corpus)
dtm.toarray()
# 실행 결과
array([[0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 2, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0]]fit_transform을 통해 원시 문서에 있는 모든 토큰의 어휘 사전을 학습하고, 문서를 단어 빈도수가 들어 있는 DTM(Document Term Matrix, 문서 용어 매트릭스)로 변환한다.
vocab = cvect.get_feature_names_out()
vocab
# 실행 결과
array(['거리두기', '거리두기와', '문의입니다', '버스', '상생지원금', '선별진료소', '승강장', '안내입니다',
'요금', '운행시간', '운행시간과', '위치', '지하철', '코로나', '택시', '터미널'],
dtype=object)CountVectorizer 객체의 get_feature_names_out()을 통해 구성 토큰을 확인할 수 있다.
df_dtm = pd.DataFrame(dtm.toarray(), columns=vocab)
df_dtmDTM를 데이터프레임으로 만들면 아래와 같다.

각 문서별 특정 토큰이 몇 회 등장했는지 확인할 수 있다.
df_dtm.sum()
# 실행 결과
거리두기 1
거리두기와 1
문의입니다 6
버스 2
상생지원금 1
선별진료소 1
승강장 2
안내입니다 2
요금 1
운행시간 1
운행시간과 1
위치 1
지하철 3
코로나 4
택시 1
터미널 1전체 문서군에서 특정 토큰이 총 몇 회 등장했는지 sum()을 통해 확인했다.
DTM 반환 함수 활용
def display_transform_dtm(cvect, corpus):
"""
모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수
"""
dtm = cvect.fit_transform(corpus)
vocab = cvect.get_feature_names_out()
df_dtm = pd.DataFrame(dtm.toarray(), columns=vocab)
return df_dtm.style.background_gradient()재사용성을 위해 함수를 작성했다.
N-grams
토큰을 몇 개 묶어서 사용할 것인지를 구분한다. 기본값은 (1,1)로 되어 있어 1개의 토큰을 사용한다.
사용법 : ngram_range(min, max)
의미 : min <= 토큰의 개수 n <= max
cvect = CountVectorizer(ngram_range=(1, 2))
display_transform_dtm(cvect, corpus)ngram_range를 지정하여 1개~2개의 토큰을 묶어 사용하도록 했다.
함수에서 반환된 DTM 데이터프레임 style.background_gradient()는 아래와 같다.

cvect = CountVectorizer(ngram_range=(2, 3))
display_transform_dtm(cvect, corpus)이번엔 2개~3개의 토큰을 묶어 사용하도록 설정했다.

ngram_range 아규먼트에 따라 다른 행렬이 반환되는 것을 확인할 수 있다.
min_df
- min_df=int : 빈도수를 의미
- min_df=float : 비율을 의미
cvect = CountVectorizer(min_df=2)
display_transform_dtm(cvect, corpus)min_df=2를 통해 2보다 낮은 빈도의 용어는 무시한다.

2회에 못 미치게 등장한 용어인 "거리두기", "터미널" 등이 보이지 않는다.
min_df는 오타, 희귀 단어 등을 제거하는 효과가 있다.
max_df
- min_df와 마찬가지로 실수로 지정하면 비율, 정수로 지정하면 빈도수를 의미한다.
cvect = CountVectorizer(max_df=0.7)
display_transform_dtm(cvect, corpus)min_df=0.7을 통해 70%보다 많이 등장하는 용어는 무시한다.

너무 자주 등장하는 "문의입니다"는 무시되었다.
max_df는 자주 등장하지만 큰 의미가 없는 용어를 제거하는 효과가 있다.
max_features
기본값은 None이며, Vectorizer가 학습할 어휘의 양을 제한한다.
corpus 중 빈도수가 높은 순으로 지정한 개수만큼만 추출한다.
cvect = CountVectorizer(max_features=5)
display_transform_dtm(cvect, corpus)빈도수 상위 5개만 추출하도록 지정했다.

max_features는 계산 시간 단축을 위해 단어 수를 제한하는 것이다.
stop_words
주로 불용어를 제거하고 싶은 경우에 지정
stop_words=["코로나", "문의입니다", '승강장']
cvect = CountVectorizer(stop_words=stop_words)
display_transform_dtm(cvect, corpus)"코로나", "문의입니다", "승강장"을 지정하여 무시한다.

stop_words는 우리, 그, 그리고, 그래서 등 문장 내에서 큰 의미를 갖지 않는 단어를 주로 지정한다.
analyzer
기능의 단어 단위, 캐릭터 단위 동작을 정한다.
기본값은 'word'이며, 'char', 'char_wb'를 지정할 수 있다.
cvect = CountVectorizer(analyzer='char', ngram_range=(3, 7), max_features=30)
display(display_transform_dtm(cvect, corpus))
cvect.get_feature_names_out()3~7개 캐릭터 단위 토큰화를 지정했고 최대 30개까지로 제한하면 아래와 같다.

단어 사이의 띄어쓰기도 포함하여 토큰화한다.
예시로 '지하철 승강장 문의입니다'에서 장과 문 사이에 띄어쓰기가 있으나 "강장문", "강장문의" 등으로 같이 묶인 것을 확인할 수 있다.
cvect = CountVectorizer(analyzer='char_wb', ngram_range=(3, 7), max_features=30)
display(display_transform_dtm(cvect, corpus))
cvect.get_feature_names_out()이번에도 3~7개 캐릭터 단위 토큰화, 최대 30개 토큰으로 제한했지만 'char_wb' 지정으로 띄어쓰기가 들어있으면 같이 묶지 않는다.

'char'와 'char_wb'의 차이점을 이해하자.
TfidVectorizer
사이킷런에서 TF-IDF 가중치를 적용한 단어 벡터를 만들 수 있는 방법
바로 실습해 보자.
tfidfvect = TfidfVectorizer()
display(display_transform_dtm(tfidfvect, corpus))변환 결과는 아래와 같다.

TF-IDF는 특정 문서에서 자주 등장하는 단어는 중요도가 높지만, 모든 문서에서 자주 등장하는 단어는 오히려 중요도가 낮다고 판단한다.
다양한 파라미터를 사용해 보자.
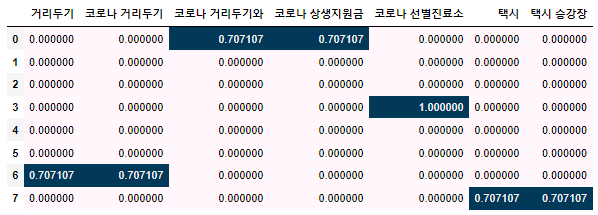
tfidfvect = TfidfVectorizer(analyzer='word',
ngram_range=(1,2),
max_features=7,
min_df=0.1, max_df=1)
display_transform_dtm(tfidfvect, corpus)word 단위로, 1~2개씩 묶어서, 10% 이상, 1 이하의 토큰을 최대 7개로 제한하여 확인
다양한 방법으로 BoW(Bag of Words)를 만드는 방법을 익혔다.
자연어 처리의 기본적이면서도 매우 중요한 부분을 배운 것 같다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 65] Numpy를 이용한 SVD(특이값 분해) (0) | 2023.03.30 |
|---|---|
| [DAY 64] 뉴스 토픽 분류 - KoNLpy, 어간 추출, 불용어 제거, TfidfVectorizer (0) | 2023.03.28 |
| [DAY 62] Tableau 분산형 차트, 히스토그램, 박스플롯 (0) | 2023.03.25 |
| [DAY 61] Week 14 Insight Day 미니프로젝트4 시작, 미드프로젝트1 리뷰 리포트 (0) | 2023.03.23 |
| [DAY 60] CatBoost, 하이퍼파라미터 튜닝 (0) | 2023.03.22 |



댓글