벌써 Special Lecture 통계의 마지막 날이 됐다.
통계는 배울수록 어려운 것도 많지만 재미있는 것도 많은 것 같다.
모형 선택
과대적합(overfitting)
- 최소제곱법은 잔차분산이 가장 작은 계수를 추정
- 주어진 표본에 가장 맞는 계수를 찾게 된다
- 표집 오차가 존재하기 때문에, 주어진 표본에 지나치게 맞는데 계수를 추정하면 모집단의 계수와 다를 수 있다
독립변수의 개수와 과적합
- 최소제곱법은 잔차분산이 작아지는 방향으로 계수를 추정
- 종속변수와 아무 관련이 없는 독립변수를 추가하더라도 잔차분산이 커지는 경우는 없다
- 모집단에서는 아무 관련이 없어도 표본에서는 약간의 관계라도 있을 수 있으므로 잔차분산은 작아지게 된다
- 독립변수가 많으면 많을 수록 잔차분산은 무조건 작아진다(R제곱은 높아진다)
수정 R제곱과 AIC, BIC
- 여러 모형을 비교할 때 R제곱을 사용하면 독립변수가 많은 모형에 편향
- 독립변수의 개수를 이론적으로 보정한 수정 R제곱, AIC, BIC 등의 지수가 있다.
- 수정 R제곱: R제곱을 보정 → 클 수록 좋다
- AIC와 BIC: 잔차분산을 보정 → 작을 수록 좋다
교차 검증(cross validation)
교차 검증
- '훈련 데이터셋'을 이용해 추정 후, 별개의 '테스트 데이터셋'을 이용하여 모형의 예측 성능을 검증하는 방법
- 수정R제곱, AIC, BIC 등은 이론적 보정이므로 과적합을 정확히 반영하지 못한다.
- 데이터가 충분히 많다면, 데이터를 여러 개의 셋으로 나누어 교차 검증
- 한 데이터셋의 분석 결과를 다른 데이터셋에 적용하여 예측 오차를 확인 (예측 오차가 적은 모형이 좋은 모형)
- 이론적 가정에 의존하지 않으므로 데이터가 충분히 많을 때는 교차 검증을 권장
교차 검증의 결과
훈련 오차와 테스트 오차가 모두 높은 경우 : 과소적합
- 모형을 복잡하게 수정 필요
훈련 오차와 테스트 오차가 모두 낮은 경우: 바람직
훈련 오차는 낮고, 테스트 오차는 높은 경우 : 과대적합
- 모형을 단순하게 수정 필요
단계적 회귀분석(stepwise regression)
단계적 회귀분석
- 독립변수의 후보가 k개 있으면 가능한 독립변수의 조합은 2^k개
- 독립변수의 후보가 많으면 모든 조합으로 회귀분석을 실시하는 것은 현실적으로 불가능
- 단계적 회귀분석(stepwise regression): 독립변수를 하나씩 추가/제거 하여 종속변수를 잘 예측하는 변수들을 선택하는 기법
- 예측력이 (통계적으로) 유의한 예측변수들만을 골라준다.
- 오직 자료만으로 변수를 선택하기 때문에 이상한 결과가 생길 수 있다.
- 단계적 회귀분석은 탐색적으로 주요 변수를 파악하는 목적으로만 실시해야한다.
전진 선택(forward selection)
독립변수를 하나씩 추가하는 방법
예시 : A, B, C, D를 가지고 Y를 예측하는 전진 방식의 단계적 회귀분석을 한다면,
- A, B, C, D 중 설명력이 제일 큰 예측변수? A
- A+B, A+C, A+D 중에 설명력이 가장 큰 조합은? A+B
- A와 A+B의 설명력이 유의하게 차이가 나지 않으면 중단
- 설명력이 유의하게 차이가 나면 A+B+C, A+B+D 중에 설명력이 가장 큰 조합을 찾는다
- 이상의 과정을 반복
후진 제거(backward elimination)
독립변수를 하나씩 제거하는 방법
예시 : A, B, C, D를 가지고 Y를 예측하는 후진 방식의 단계적 회귀분석을 한다면,
- A+B+C+D에서 설명력이 가장 적게 줄어드는 변수를 제거 (D라고 하자)
- A+B+C와 A+B+C+D 설명력이 유의하게 차이가 나면 중단
- 차이가 나지 않으면 A+B+C에서 설명이 가장 적게 줄어드는 변수를 제거한다.
- 이상의 과정을 반복
단계적 회귀분석에서 주의할 점
- 변수를 순서대로 선택하기 때문에 검토하지 못하는 조합이 생긴다
- A -> A+B -> A+B+C ... 순으로 탐색을 하면 B+C는 검토할 기회가 없다
- 전진 방식과 후진 방식의 결과가 항상 같은 건 아니다
- 대체로 전진 방식이 후진 방식보다 적은 변수를 선택하는 경향이 있다
다중공선성(multicolinearity)
다중공선성
- 독립변수들이 서로 예측가능할 경우
- 추정치가 불안정해진다 : 데이터 또는 모형의 작은 변화에 따라 추정치가 크게 달라질 수 있다
다중공선성이 생기는 원인
- 자료 자체에 서로 깊이 관련이 있는 변수들이 있는 경우
- 자료의 수학적 변환 과정에서 다중공선성이 있는 변수가 만들어지는 경우
- 예시 : 변수 x를 제곱하여 x 제곱을 만든 경우
다중공선성 해결 방법
- 데이터의 일부만으로 회귀분석을 수행해서 분석 결과에 차이가 나는지 확인
- 데이터를 더 많이 수집
- 상호작용 등의 경우 독립변수를 표준화 또는 평균중심화
- 불필요한 더미 변수를 제거 (예: 범주가 3종일 때 더미변수도 3종이면 다중공선성이 생긴다)
- VIF(Variance Inflation Factor, 분산팽창계수)가 높은 독립변수를 제거
- 정칙화(regularization)
- 해결하지 않는다
잔차 분석
잔차의 분포에서 주목하는 특성들
- 왜도, 첨도, 정규성, 자기상관
- 예측만 잘 된다면 크게 중요하지는 않으나, 모형을 개선하는 힌트를 준다 (비선형적 요소 포함 등)
왜도와 첨도
왜도(skewness) : 분포의 비대칭성
- 왜도 > 0 : 긴 꼬리가 오른쪽
- 왜도 < 0 : 긴 꼬리가 왼쪽
첨도(kurtosis) : 분포가 한 점에 몰린 정도(정규분포의 첨도 = 3)
- 첨도가 높다(첨도 > 3) → 데이터가 중심에 몰려 있다
- 첨도가 낮다(첨도 < 3) → 데이터가 바깥으로 퍼져 있다
정규성(normality)
잔차가 정규분포에 가까운 성질을 가지고 있는가?
- Jarque-Bera 검정: 잔차가 정규분포를 따른다는 귀무가설을 검정
- Q-Q 플롯: 정규분포를 따른다고 할 때, 이론적 예측값과 실제값을 비교한 플롯
등분산성
- 모든 범위에서 잔차 분산이 일정한 성질
- 예측값과 잔차를 산점도로 그려 시각화(scatter plot)
변수의 변형
변수의 변형
- 선형 모형은 독립변수와 종속변수의 선형적 관계를 가정한다는 한계
- 독립변수를 비선형 변환하면 이 한계를 일부 극복할 수 있다
- 비선형적인 것을 일부 도입하면서도 선형 모형의 틀 안에 있는 형태
로그 함수
- 오른쪽 위로 갈 수록 완만해지는 형태
- 가로축에서 1, 10, 100이 세로축에서 같은 간격(예: 0, 1, 2)
- 데이터에 적용하면 오른쪽을 왼쪽으로 끌어당기는 효과
- 독립변수에 오른쪽으로 크게 떨어져 있는 값이 있는 경우(예: 소득), 로그함수를 적용해주면 간격을 일정하게 만들어 줄 수 있다
I 함수
- 관계식에 덧셈, 곱셈, 거듭제곱 등을 할 경우 적용이 불가
- I 함수를 사용하여 이러한 계산을 적용 가능
- 두 독립변수 x와 z를 더하여 하나의 변수로 변환
- 예시 : price ~ I(my_car_damage + other_car_damage)
- 2차항 추가도 가능
- y ~ I(x**2) + x 형식
상호작용(interaction)
상호작용
- 두 독립변수의 곱으로 이뤄진 항(xm)
- y = x + m + xm
- 관계식으로 쓸 때는 :을 사용
- y ~ x + m + x:m
- 주의 : 관계식에서 x*m은 x+m+x:m과 같다
상호작용의 간단한 예
- 이해를 돕기 위한 간단한 예시
- x는 연속형
- m은 0 또는 1만 갖는 범주형 변수 (설명의 편의를 위한 단순화)
상호작용이 없는 경우
y ~ x + m
- m에 따라 x의 절편이 바뀌는 것으로 해석

기울기가 달라지는 경우
y ~ x + x:m
- m에 따라 x의 기울기가 바뀌는 것으로 해석

기울기와 절편이 모두 달라지는 경우
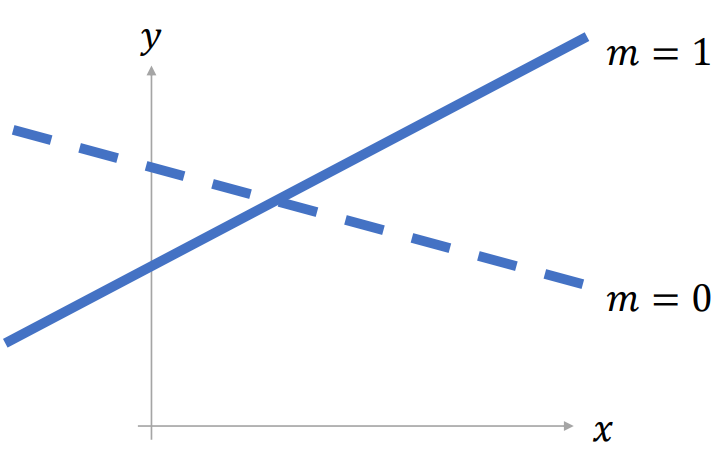
y ~ x + m + x:m
인과효과
평행 추세의 가정(parallel trend assumption)
- 처치 효과가 없다면 실험군 A와 실험군 B가 비슷하게 변할 것이라고 가정
- 이러한 가정이 성립하지 않는다면 이중차분법의 결과는 무의미
- 가능한 비슷한 A와 B를 비교하는 것이 중요
예시 : 광고를 하지 않아도 시간이 흐름에 따라 매출이 오를 것이라고 가정
통계 강의가 마무리되었다.
재미있는 스토리도 많았고 이론도 많았다.
시간 관계상 뒤쪽 파트를 하지 못한 것이 아쉽다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 40] 미드프로젝트1 - 카페 브랜드별 전국 매장 정보 병합, 커피지수 계산 (0) | 2023.02.21 |
|---|---|
| [DAY 39] 미드프로젝트1 시작, 카페 체인별 매장 정보 수집과 전처리 (0) | 2023.02.20 |
| [DAY 37] 상관 분석, 상관 계수, 상관과 인과, 심슨의 역설, 회귀 분석, 다중 회귀 분석 (0) | 2023.02.17 |
| [DAY 36] 효과 크기, 대응표본 t-검정, 분산 분석, 카이제곱 검정, 맥니마 검정 (0) | 2023.02.15 |
| [DAY 35] 표집(sampling), 추정, 통계적 가설 검정, A/B 테스트 (0) | 2023.02.14 |




댓글