한 도시의 발전 수준은 (버거킹 개수 + 맥도날드 개수 + KFC 개수) / 롯데리아 개수 값에 비례한다는 말이 사실일까?
실제 각 버거 체인점 개수를 확인하여 분석해봤다.
데이터 준비
공공데이터포털에 공개된 소상공인시장진흥공단_상가(상권)정보를 사용한다.
각 시,도별 데이터를 glob과 반복문을 이용해 모두 pandas로 로드하였고 concat을 통해 하나의 데이터프레임 df로 합쳤다.
원본 데이터는 상가업소번호부터 지점명, 업종분류코드, 건물관리번호, 우편번호, 동, 층 정보 등 39개의 column을 가진 데이터였다.
중복 데이터 제거, 상호명이 결측치인 데이터 제거 후 사용할 컬럼만 남겼다.
cols = ['상호명', '상권업종대분류명', '시도명', '시군구명', '도로명주소', '경도', '위도']
df = df[cols].copy()
dfcopy()를 사용하여 깊은 복사를 했다.

250만 rows가 넘는 데이터를 확인할 수 있다.
이정도 양의 데이터는 엑셀로 처리할 수가 없다. 이것이 파이썬을 활용하는 이유 중 하나다.
버거킹, 맥도날드, KFC, 롯데리아 데이터 추출
먼저 상호명의 알파벳을 모두 대문자로 바꾼 "상호명_대문자" 컬럼을 추가하고 그 컬럼을 str.contains를 통해 활용한다.
df_burger = df.loc[(df['상호명_대문자'].str.contains('버거킹|BKR|맥도날드|맥도널드|롯데리아|KFC|케이에프씨'))
& (df["상권업종대분류명"].isin(["음식", "소매", "생활서비스"])), :]
df_burger원하는 버거 체인점만 추출한 결과는 아래와 같다.

전국에서 2134개의 매장을 찾았다.
전국 각 시도별, 브랜드별 매장 수
같은 브랜드더라도 상호명이 지점별로 다르기 때문에 "브랜드" 파생변수를 만든다.
brand_dct = {'버거킹': '버거킹|BKR',
'맥도날드': '맥도날드|맥도널드',
'KFC': 'KFC|케이에프씨',
'롯데리아': '롯데리아'}
for brand, val in brand_dct.items():
df_burger.loc[df_burger['상호명_대문자'].str.contains(val), '브랜드'] = brand
df_burger.loc[:, ['상호명', '브랜드']].head()딕셔너리와 반복문을 활용하여 "브랜드"를 추가하였다.

샘플을 통해 상호명과 브랜드를 확인한 결과 잘 적용된 것을 확인할 수 있다.
groupby를 이용하여 시도별 브랜드별 상호명 수를 계산한다.
df_sido = df_burger.groupby(['시도명', '브랜드'])['상호명'].count()
df_sido = df_sido.unstack().fillna(0).astype(int)
df_sido['합계'] = df_sido.sum(axis=1)
df_sido결측치는 0으로 채워주며 합계를 계산하였다.

seaborn의 heatmap을 통해 전체 스케일을 비교한다.

style.background_gradient를 사용하면 아래와 같다.

heatmap은 전체 스케일 비교에 적합하며 style.background_gradient는 각 변수별 비교에 적합하다.
예시로 부산의 롯데리아와 맥도날드는 거의 같은 값이다. 이 값들은 heatmap에서 거의 같은 색으로 표시되었으나style.background_gradient는 롯데리아별, 맥도날드별 비교이므로 맥도날드가 진하게 나타났다.
시도별 버거지수 계산
방금 구한 df_sido에서 버거지수를 구해 파생변수를 만든다.
df_sido["버거지수"] = round((df_sido['버거킹'] + df_sido['맥도날드'] + df_sido['KFC']) / df_sido['롯데리아'], 2)
df_sido = df_sido.sort_values('버거지수', ascending=False)
df_sido(합계 - 롯데리아) / 롯데리아 방식으로도 같은 값이 나온다.

시도별 위도, 경도 평균값
groupby와 agg를 사용한다.
df_sido_latlog = df_burger.groupby('시도명').agg({'위도': 'mean', '경도': 'mean'})
df_sido_latlong = pd.concat([df_sido, df_sido_latlog], axis=1)
df_sido_latlong위도, 경도 평균값을 구하고 먼저 구한 df_sido와 concat한다.

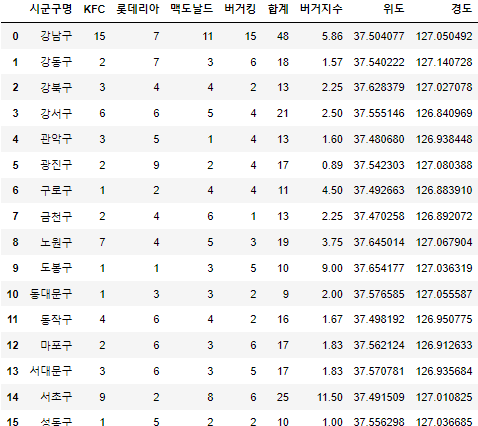
서울시 구별, 브랜드별 매장 수
전국 시도별, 브랜드별 매장 수를 구할 때와 같은 방식으로 시군구별, 브랜드별 매장 수를 구한 후 서울특별시만 추출하였다.

해당 데이터의 버거 브랜드로 히트맵을 그리면 아래와 같은 결과를 얻을 수 있다.

강남구, 송파구, 서초구에 버거 매장이 많이 분포된 것이 확인된다.
상관 계수
간단히 말하면 두 변수 사이의 관계의 강도를 표현하는 것이다.
0이면 선형 관계가 없는 것이고, -1에 가까울수록 강한 음의 관계, 1에 가까울수록 강한 양의 관계다.
두 변수 사이의 연관성을 나타낼 뿐이며 인과관계를 의미하는 것은 아니다.
전국 기준 브랜드별 상관계수 확인
brand_list = ['버거킹', '맥도날드', 'KFC', '롯데리아']
df_sigungu[brand_list].corr()전국단위로 브랜드별 상관계수를 확인한다.

seaborn의 pairplot을 그리면
sns.pairplot(df_sigungu[brand_list], corner=True, kind="reg")회귀선을 포함하여 그려준다.

서로서로 양의 상관관계가 있는 것을 확인할 수 있다
서울시 기준 브랜드별 상관계수 확인
서울시의 매장만 보면 아래와 같이 나타난다.

pairplot도 비교해보자.

맥도날드와 KFC 사이에 강한 양의 상관관계가 확인된다.
CircleMarker 시각화
CircleMarker를 사용하기 위해 folium을 import하고 위,경도(latlong)를 계산하였다.
이후 folium.Map과 folium.CircleMarker를 사용해서 서울시 내의 버거 매장을 표시하였다.
f_map = folium.Map(latlong, zoom_start=12, tiles="Stamen Toner")
# dataframe의 인덱스만 가져와서 순회
for i in df_seoul.index:
sub_lat = df_seoul.loc[i, "위도"]
sub_long = df_seoul.loc[i, "경도"]
brand = df_seoul.loc[i, '브랜드']
title = f"{df_seoul.loc[i, '상호명']} - {df_seoul.loc[i, '도로명주소']}"
color = {"롯데리아" : "yellow", "버거킹": "blue", "맥도날드": "orange", "KFC":"red"}
folium.CircleMarker([sub_lat, sub_long],
radius=3,
color=color[brand],
tooltip=title).add_to(f_map)
f_map롯데리아 노란색, 버거킹 파란색, 맥도날드 주황색, KFC는 빨간색 원으로 표시된다.
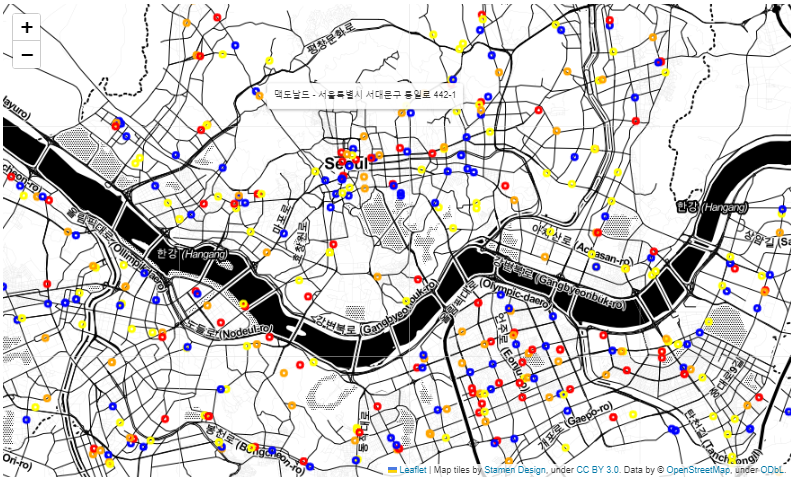
원에 마우스를 올리면 사진과 같이 매장 정보가 표시된다.
Choropleth Map
plotly choropleth
시도별, 시군구별 구분을 위해 GeoJSON을 활용했다.
ko_geojson에는 전국 시도별 데이터를, seoul_geojson에는 서울 구별 데이터를 로드했다.
먼저 서울시 데이터를 시각화해보자.
위 데이터프레임을 choropleth map으로 시각화한다.
import plotly.express as px
fig = px.choropleth(df_seoul_index,
geojson=seoul_geojson,
color="버거지수",
locations="시군구명",
featureidkey="properties.name",
labels="시군구명",
projection="mercator",
color_continuous_scale=px.colors.colorbrewer.Reds)
fig.update_geos(fitbounds="locations", visible=False)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})버거지수가 높을수록 빨간색이 짙어지는 서울 지도가 나온다.
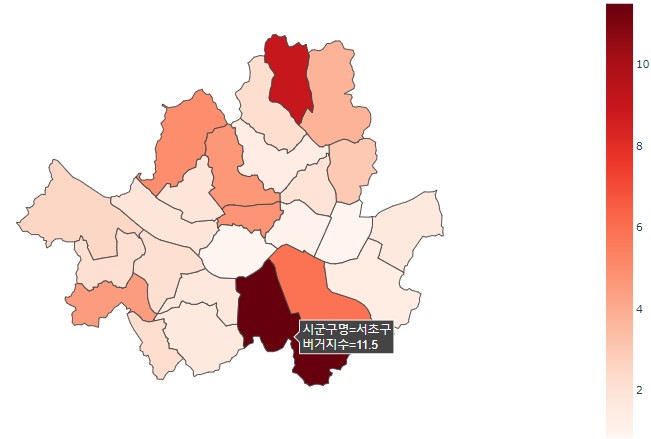
color_continuous_scale 값을 변경해서 다른 색상으로 그려볼 수도 있다.
plotly는 동적 시각화를 제공하므로 사진처럼 마우스를 올려 구별 값을 확인할 수 있다.
전국 데이터 시각화
전국 시도별 버거지수를 choropleth map으로 시각화한다.
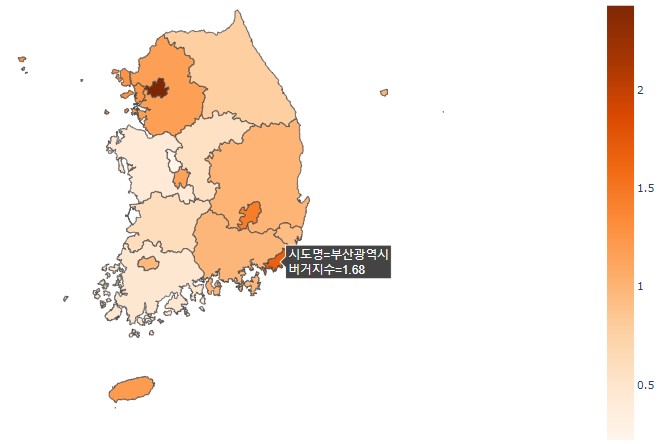
우리나라의 전국 시도별 버거지수를 plotly를 이용해 시각화하였다.
folium choropleth
서울 구별 버거지수 시각화
f_map = folium.Map(latlong, zoom_start=11)
folium.Choropleth(
geo_data=seoul_geojson,
name='choropleth',
data=df_seoul_index,
columns=['시군구명', '버거지수'],
key_on='feature.properties.name',
fill_color='Blues',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='버거지수'
).add_to(f_map)
f_map이번에는 plotly가 아닌 folium으로 서울 버거지수 지도시각화를 한다.
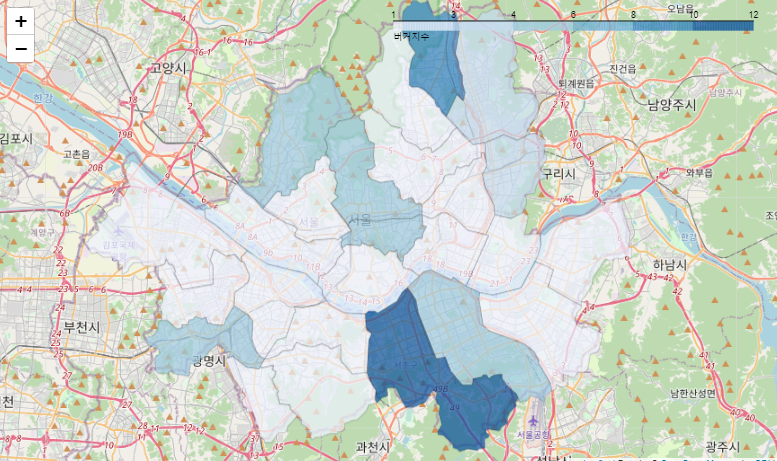
plotly를 사용했을 때와 다소 다른 지도를 얻는다.
전국 시도별 버거지수 시각화
# 전국 Choropleth map
f_sido_map = folium.Map([36.3, 127.5], zoom_start=6.5, tiles='Stamen Toner')
folium.Choropleth(
geo_data=ko_geojson,
name='choropleth',
data=df_sido_index,
columns=['시도명', '버거지수'],
key_on='feature.properties.name',
fill_color='Blues',
fill_opacity=0.9,
line_opacity=0.2,
legend_name='버거지수'
).add_to(f_sido_map)
f_sido_maptiles를 지정하여 서울과 시각적 표현이 다르다.
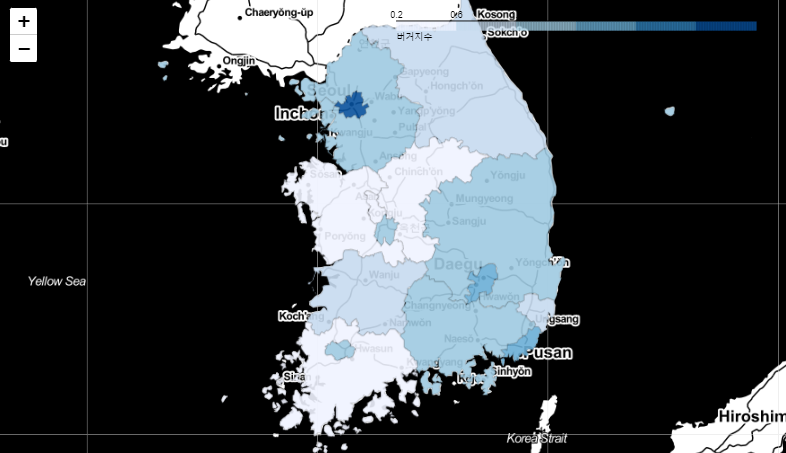
버거지수를 구해보고, 상관계수를 살펴보고, plotly와 folium으로 지도시각화까지 해봤다.
버거지수 = (버거킹 개수 + 맥도날드 개수 + KFC 개수) / 롯데리아 개수 값과 도시의 발전도가 비례한다는 얘기는 어느정도 맞는 것 같다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 33] SQL 마지막 날 - 추천도서, 내용 정리, 연습문제 (0) | 2023.02.12 |
|---|---|
| [DAY 32] Week 8 Insight Day 미드프로젝트1 공지, 나 사용법 (0) | 2023.02.09 |
| [DAY 30] EDA - 국가,권역별 전산업,소부장 산업별 수출/수입금액 (0) | 2023.02.07 |
| [DAY 29] Tidy Data(깔끔한 데이터), melt, 아파트 분양가 분석 (0) | 2023.02.07 |
| [DAY 28] SQL 데이터 집계하기 - ROLLUP, WINDOW FUNCTION (0) | 2023.02.03 |



댓글