최초 데이터를 Tidy Data로 만드는 등 전처리 과정을 거치고 EDA하였다.
데이터 시각화는 plotly와 seaborn을 활용하였다.
최초 데이터 확인
데이터를 pandas로 로드하여 변수 raw에 저장하였다.
데이터 출처는 공공데이터포털이다.
raw.head(3)raw를 확인해보면

연도와 월 값이 옆으로 쭉 늘어져 있는 형태임을 알 수 있다.
208행 132열의 구조를 가지고 있었다.
또한 결측치를 확인해보자.
sns.heatmap(raw.isnull(), cmap='gray_r')seaborn의 heatmap을 사용하여 확인해보면

검은색으로 특정 열에 결측치가 있음을 확인할 수 있다.
데이터 전처리
앞 4개의 컬럼은 분석하기 좋은 형태로 되어있으므로 해당 컬럼들을 기준으로 raw를 melt하여 Tidy Data로 만든다.
df = raw.melt(id_vars=raw.columns[:4], var_name='연월', value_name='달러')
df.head()var_name과 value_name에 값을 넣어 컬럼 이름을 지정하였다.

깔끔한 형태의 데이터가 되었다. 이 과정에서 열에 있던 데이터가 행으로 녹는 형식으로 변화했다.
이후 결측치 제거, 필요한 컬럼만 채택, 컬럼명 변경, 텍스트 전처리, 파생변수 생성 과정 등의 전처리를 거쳐 최종적으로 데이터프레임은 아래처럼 되었다.

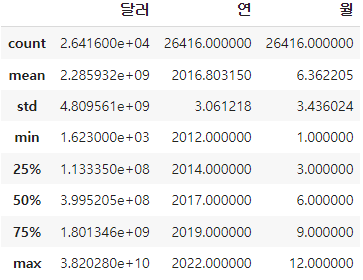
통계값 확인
전처리 후 수치형, 범주형 변수에 대한 describe와, histogram을 확인한 결과는 아래와 같다
.

데이터 시각화
국가권역 컬럼의 unique 값을 확인해보면

위와 같이 52개인 것을 확인할 수 있다.
이처럼 unique 값 개수가 너무 많으면 데이터프레임을 다룰 때 어려움이 발생하므로 권역과 국가로 나누어 각각 df_world, df_country 변수에 저장한 후 진행한다.
world = ['아시아', '중동', '유럽', '북미', '중남미', '아프리카',
'오세아니아', '기타지역', 'EU(27)', 'OECD', 'ASEAN',
'LAIA', '선진국', 'OPEC', '개발도상국']
df_world = df[df["국가권역"].isin(world)].copy()
df_country = df[~df["국가권역"].isin(world)].copy()
df_world.shape, df_country.shape
px.histogram(df_world, x='달러', y='국가권역', histfunc='sum')plotly의 히스토그램을 그린다. 권역별 수입/수출액 총합이 계산된다.

plotly는 javascript 기반의 동적 시각화를 제공하므로 막대에 마우스를 올려서 사진처럼 값을 확인할 수도 있다.
px.histogram(df_country, x='달러', y='국가권역', histfunc='sum', height=700)이번엔 국가별 수입/수출액 총합을 확인한다. 국가가 잘리는 것을 방지하기 위해 height를 지정한다.

국가별 수입/수출액 총합 그래프를 확인한 결과 중국이 4 Trillion 달러를 넘기는 압도적인 값으로 나타난다.
조금 더 시각적인 그래프를 그려보면
px.histogram(df_country,
x='달러',
y='국가권역',
color='항목',
height=700
).update_yaxes(categoryorder='total ascending')color에 항목을 지정하고 정렬을 적용한 결과로

위와 같은 그래프를 확인할 수 있다.
수출, 수입 항목별 막대가 중첩되어있으며 국가별 순위가 명확히 보인다.
다른 형태로는
px.histogram(df_country,
x='달러',
y='국가권역',
color='항목',
barmode='group',
height=700
).update_yaxes(categoryorder='total ascending')barmode='group'을 지정하여
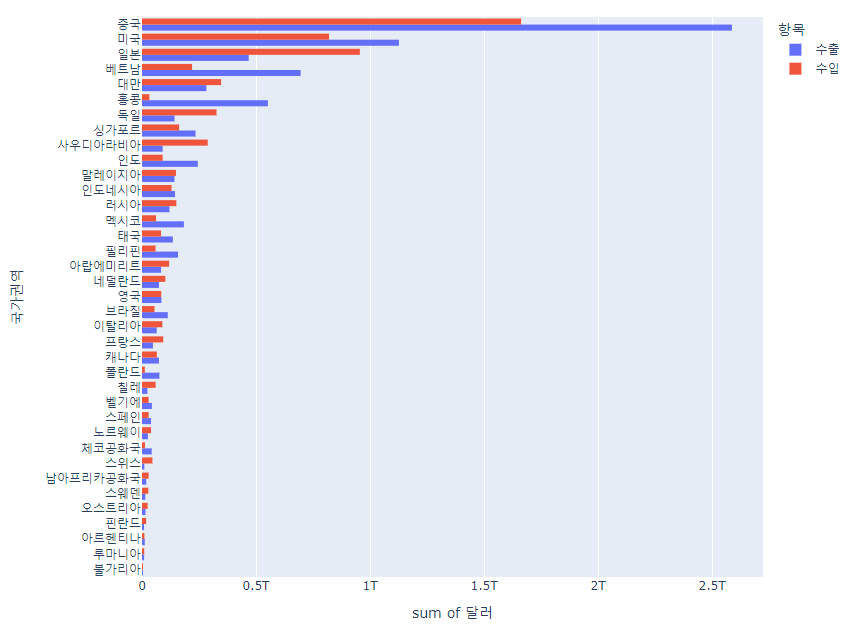
수출, 수입 막대를 중첩하지 않고 확인하는 방법과
(홍콩의 수출액, 수입액 차이가 눈에 띈다)
px.histogram(df_country,
x='달러', y='국가권역',
color='항목', facet_col='항목',
histfunc='sum', height=700)facet_col을 color와 같은 항목으로 지정하여
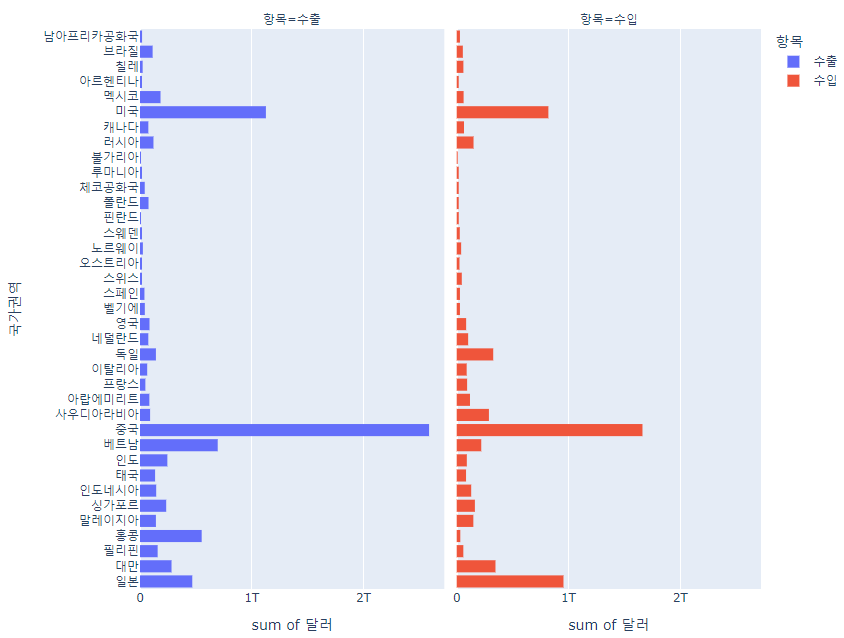
항목을 각각의 그래프로 확인하는 방법이 있다.
이 경우에는 위에서 했던 정렬이 동작하지 않는다.
px.histogram(df_country,
x='달러', y='국가권역',
color='항목', facet_col='산업',
histfunc='sum', height=700)이번엔 color는 항목으로, facet_col은 산업으로 지정하였다.
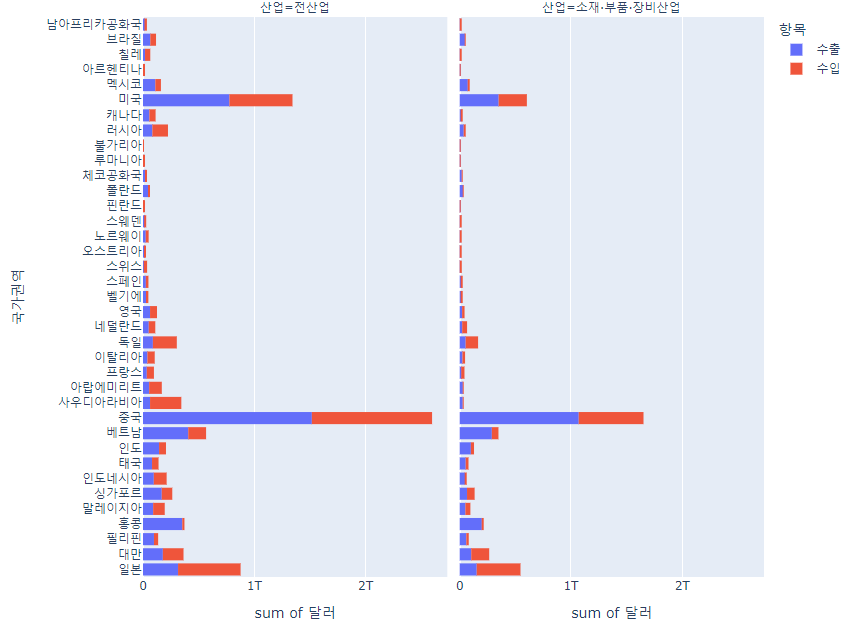
좌우 그래프가 각 산업을 의미하게 되었고 항목은 중첩 막대그래프로 표현되었다.
barmode='group'을 지정하면 막대가 중첩되지 않는다.
seaborn의 catplot을 사용하여 시간의 흐름에 따른 추이를 그려보자.
sns.catplot(data=df, x="연", y="달러",
hue="항목", col="산업",
estimator=np.sum, col_wrap=2,
kind="point", errorbar=None)point plot을 그린다.
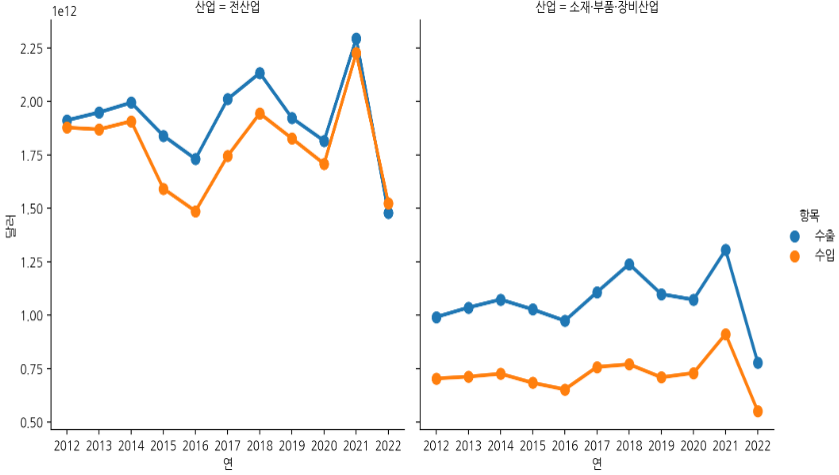
산업별로 2012~2022 연도별 수출,수입액 추이를 확인할 수 있다. 각 연도별 값은 해당 연도의 총액이다.
국가별로도 확인할 수 있다. 그러나 국가 수가 너무 많기 때문에 우리나라 주요 무역국들의 추이를 확인한다.
sns.catplot(data=df_country[df_country['국가권역'].isin(['일본', '중국', '미국', '러시아'])],
x="연", y="달러",
hue="항목", col="국가권역",
estimator=np.sum, col_wrap=2,
kind="point", sharex=False, errorbar=None)isin을 활용하여 일본, 중국, 미국, 러시아만 그래프를 그리도록 한다.
sharex=False를 지정하여 각 그래프마다 x축을 표시한다.
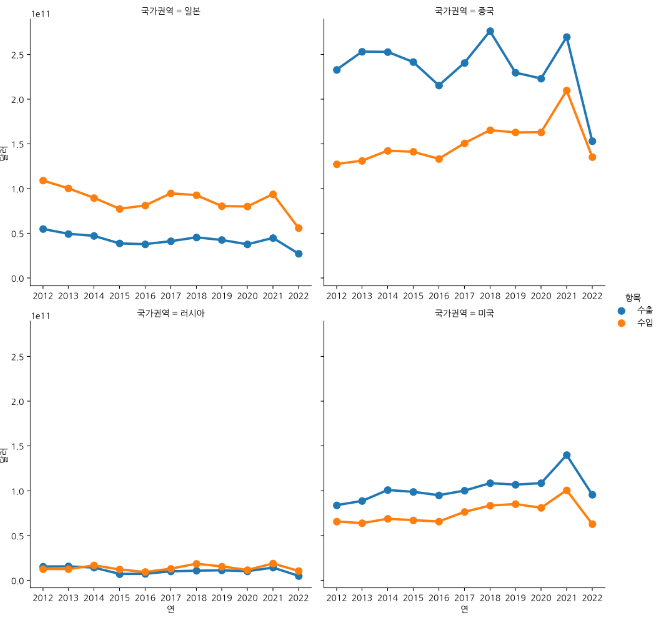
일본, 중국, 러시아, 미국의 2012~2022년 연도별 수출,수입액 총액이 point plot으로 잘 그려진 것을 확인할 수 있다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 32] Week 8 Insight Day 미드프로젝트1 공지, 나 사용법 (0) | 2023.02.09 |
|---|---|
| [DAY 31] 버거지수, 상관계수, plotly와 folium을 이용한 지도 시각화 (1) | 2023.02.09 |
| [DAY 29] Tidy Data(깔끔한 데이터), melt, 아파트 분양가 분석 (0) | 2023.02.07 |
| [DAY 28] SQL 데이터 집계하기 - ROLLUP, WINDOW FUNCTION (0) | 2023.02.03 |
| [DAY 27] Week 7 Insight Day 미니프로젝트2 시작, 수료생 특강 (0) | 2023.02.02 |



댓글