EDA를 시작했다. 서울시 코로나 확진자 데이터를 pandas DataFrame으로 다루어봤다.
실제 데이터를 분석하고 시각화해보는 시간을 가졌다.
glob
파일 목록을 간편하게 확인할 수 있는 glob 사용법을 배웠다.

코드가 작성된 파일의 현재 폴더의 data 폴더 아래에 seoul로 시작되는 폴더 아래에 seoul로 시작되는 csv 파일을 찾았다.
이처럼 glob은 파일명을 정확히 작성하지 않아도 찾을 수 있어서 유용하다.
데이터프레임 만들기
확인된 파일 중 seoul-covid19-2021-12-18.csv와 seoul-covid19-2021-12-26.csv를 pandas의 read_csv를 이용하여 각각 df_01과 df_02에 데이터프레임으로 저장하였다.
df_01은 18646 rows, df_02는 200000 rows의 데이터였으며 pandas의 concat을 이용하여 df 변수에 하나로 병합해주었다.
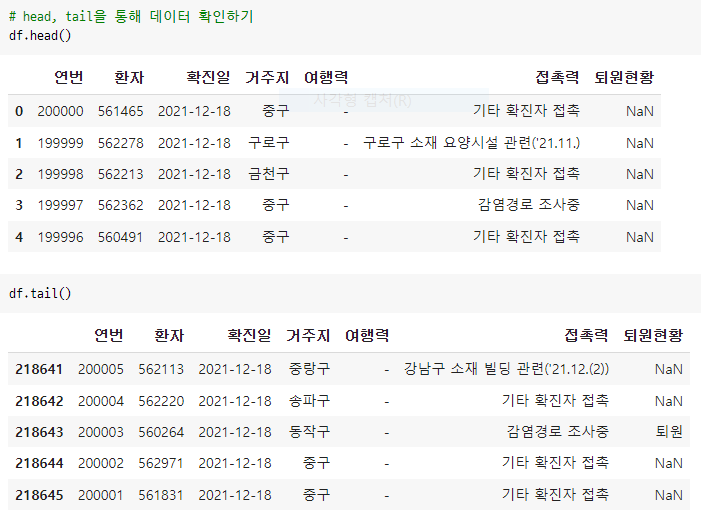
합쳐진 데이터프레임은 218646 rows이다.
2021-12-26까지 발생한 서울시 코로나 확진자 데이터프레임을 만들었다.
연번 순으로 정렬
서울시 코로나 확진자를 넘버링한 "연번"을 인덱스로 설정하고 이를 기준으로 정렬한다.
df = df.set_index('연번')
df = df.sort_index()

연번이 인덱스가 되었고 연번 오름차순으로 잘 정렬된 것을 확인할 수 있다.
데이터 요약
DataFrame의 attributes를 이용하여 df를 살펴보면
df.shape
# 실행 결과
(218646, 6)
df.dtypes
# 실행 결과
환자 int64
확진일 object
거주지 object
여행력 object
접촉력 object
퇴원현황 object
dtype: object
df.columns
# 실행 결과
Index(['환자', '확진일', '거주지', '여행력', '접촉력', '퇴원현황'], dtype='object')
df.index
# 실행 결과
Int64Index([ 1, 2, 3, 4, 5, 6, 7, 8,
9, 10,
...
218637, 218638, 218639, 218640, 218641, 218642, 218643, 218644,
218645, 218646],
dtype='int64', name='연번', length=218646)위처럼 shape, dtypes, columns, index를 각각 확인하였다.
info()를 이용하면 이러한 정보를 한 번에 확인이 가능하다.
df.info()
# 실행 결과
<class 'pandas.core.frame.DataFrame'>
Int64Index: 218646 entries, 1 to 218646
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 환자 218646 non-null int64
1 확진일 218646 non-null object
2 거주지 218646 non-null object
3 여행력 218646 non-null object
4 접촉력 218646 non-null object
5 퇴원현황 163497 non-null object
dtypes: int64(1), object(5)
memory usage: 11.7+ MB
기술통계
수치형 데이터 기술통계
df.describe()
# 실행 결과
환자
count 218646.000000
mean 322462.160977
std 173903.371149
min 2.000000
25% 168409.250000
50% 336181.500000
75% 470149.500000
max 611669.000000describe() 메소드를 아무 인자 없이 실행하면 수치형 데이터의 기술통계를 구한다.
데이터 요약에서 확인했듯 df에는 "환자" 컬럼만 수치형 데이터이기 때문에 결과가 위처럼 나온다.
결측치를 제외한 개수, 평균, 표준편차, 최솟값, 최댓값, 사분위수를 확인할 수 있다.
범주형 데이터 기술통계

describe()에 include='object' 또는 include='O'를 인자로 넣어 실행하면 범주형 데이터의 기술통계를 구한다.
"환자" 컬럼을 제외한 5개 컬럼에 대한 결과가 나온다.
결측치를 제외한 개수, unique값 개수, 최빈값, 최빈값의 빈도수를 확인할 수 있다.
날짜 데이터타입 변경
"확진일"을 datetime으로 변경하려고 한다.
df['확진일']
# 실행 결과
연번
1 2020-01-24
2 2020-01-30
3 2020-01-30
4 2020-01-30
5 2020-01-31
...
218642 2021-12-26
218643 2021-12-26
218644 2021-12-26
218645 2021-12-26
218646 2021-12-26
Name: 확진일, Length: 218646, dtype: object현재는 object 타입임이 보인다.
pandas의 to_datetime을 사용하여 데이터 타입을 변경해준다.
df['확진일'] = pd.to_datetime(df['확진일'])
df['확진일'].head()
# 실행 결과
연번
1 2020-01-24
2 2020-01-30
3 2020-01-30
4 2020-01-30
5 2020-01-31
Name: 확진일, dtype: datetime64[ns]datetime 형태로 잘 변경되었다.
파생변수 만들기
YYYY-MM-DD 형태의 확진일을 통해 연도, 월, 일, 요일 컬럼을 만든다.
df["연도"] = df['확진일'].dt.year
df["월"] = df['확진일'].dt.month
df["일"] = df['확진일'].dt.day
df["요일"] = df['확진일'].dt.weekdaydt accessor를 사용하여 파생변수를 생성하였다.
참고로 weekday, dayofweek, day_of_week은 월요일 0 ~ 일요일 6을 반환하는 모두 같은 기능을 한다.
Python은 어떤 기능을 하나의 방법으로 구현하도록 하는 지향점을 가지고 있지만 pandas는 이에 위배되는 경우가 종종 있다고한다.
이어서 YYYY-MM 형태로 연도월 컬럼도 만들어본다.
좀 전에 만든 연도와 월을 이용해서도 만들 수 있지만 아래처럼 슬라이싱으로 할 수 있다.
df["연도월"] = df['확진일'].astype(str).str[:7]
df['연도월']
# 실행 결과
연번
1 2020-01
2 2020-01
3 2020-01
4 2020-01
5 2020-01
...
218642 2021-12
218643 2021-12
218644 2021-12
218645 2021-12
218646 2021-12
Name: 연도월, Length: 218646, dtype: object
연도월을 왜 사용하는가?
아래와 같이 "월"과 "연도월"을 통해 확진자 발생 빈도를 확인하면
df['월'].value_counts().sort_index()
# 실행 결과
1 4885
2 4140
3 4288
4 5959
5 6259
6 6717
7 14785
8 17608
9 22688
10 19573
11 39171
12 72573
Name: 월, dtype: int64
df['연도월'].value_counts().sort_index()
# 실행 결과
2020-01 7
2020-02 80
2020-03 391
2020-04 156
2020-05 229
2020-06 459
2020-07 281
2020-08 2415
2020-09 1306
2020-10 733
2020-11 2904
2020-12 10432
2021-01 4878
2021-02 4060
2021-03 3897
2021-04 5803
2021-05 6030
2021-06 6258
2021-07 14504
2021-08 15193
2021-09 21382
2021-10 18840
2021-11 36267
2021-12 62141
Name: 연도월, dtype: int64"월"을 사용하면 연도의 구분을 둘 수 없고 연도에 상관 없이 확진자 수가 합쳐서 카운트되는 반면 "연도월"을 사용하여 연도와 월 기준으로 정렬함으로써 확실한 추세를 확인할 수 있었다.
요일 컬럼을 이용하여 한글 요일명 컬럼 만들기
df['요일명'] = df['요일'].map(lambda x: '월화수목금토일'[x])lambda를 사용해서 0~6의 숫자로 되어 있는 요일에서 월화수목금토일의 한글 요일명으로 변환하여 요일명 컬럼에 저장하였다.
# ["요일", "요일명"]을 sample(5) 로 임의의 5개만 불러와 잘 변환이 되었는지 확인하기
df.loc[:, ['요일', '요일명']].sample(5)
# 실행 결과
요일 요일명
연번
139068 4 금
76075 1 화
128240 2 수
43999 0 월
147861 3 목
데이터 시각화
연도월 기준으로 서울시 코로나 확진자 발생 동향을 시각화
year_month = df['연도월'].value_counts().sort_index()
year_month.plot(figsize=(12,3))plot()의 default인 선 그래프가 그려진다.
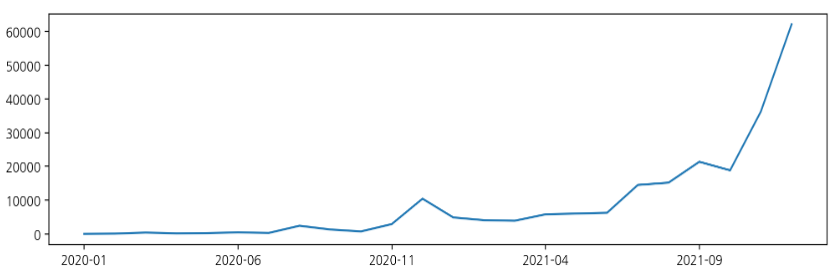
이번엔 막대 그래프를 그려본다.
year_month.plot(kind='bar', figsize=(12,3), title='월별 확진 수', rot=40)kind에 막대그래프를 지정했고, 그래프 제목과 x축 이름 회전을 지정했다.
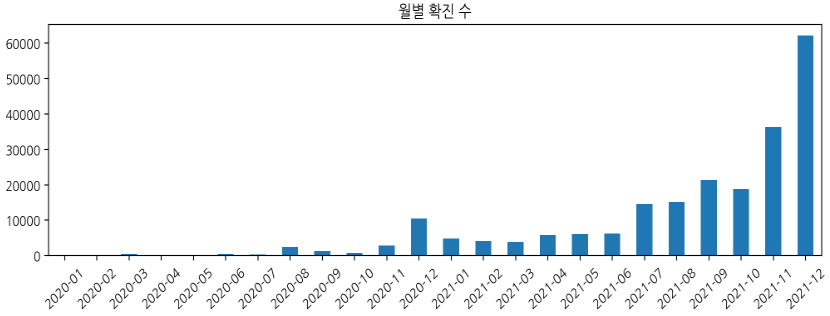
시간의 흐름에 따라 확진자 발생이 폭발적으로 늘어난 것을 시각적으로 확인할 수 있다.
요일별 확진자 수 시각화
w_count = df['요일명'].value_counts()
w_count[list('월화수목금토일')].plot.bar(figsize=(6,3), rot=0)요일명 월화수목금토일은 sort 결과 원하는대로 정렬되지 않아서 직접 지정했다.
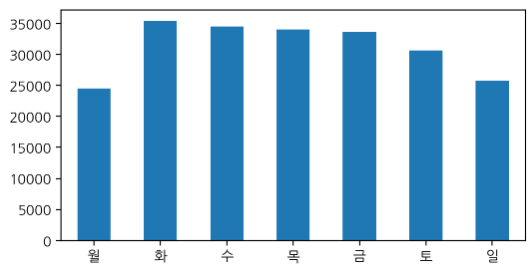
요일별로도 확진자 수에 차이가 있었다.
주말에 진료소가 운영되지 않아 요일별로 유의미한 차이를 보이는 것이 아닐까?
전체 기간 데이터
첫 확진일과 마지막 확진일자를 찾는다.
day_count = df['확진일'].value_counts().sort_index()
first_day = day_count.index.min()
last_day = day_count.index.max()
찾은 날짜와 pandas의 date_range()를 이용해서 전체 기간 데이터를 생성한다.
# pd.date_range 로 전체 기간을 생성합니다.
all_day = pd.date_range(start=first_day, end=last_day)
all_day
# 실행 결과
DatetimeIndex(['2020-01-24', '2020-01-25', '2020-01-26', '2020-01-27',
'2020-01-28', '2020-01-29', '2020-01-30', '2020-01-31',
'2020-02-01', '2020-02-02',
...
'2021-12-17', '2021-12-18', '2021-12-19', '2021-12-20',
'2021-12-21', '2021-12-22', '2021-12-23', '2021-12-24',
'2021-12-25', '2021-12-26'],
dtype='datetime64[ns]', length=703, freq='D')2020-01-24~2021-12-26의 date_range가 생성되었다.
이것을 데이터프레임으로 변환하고 확진수 컬럼을 추가한다.
df_all_day = all_day.to_frame()
df_all_day['확진수'] = day_count
df_all_day
# 실행 결과
0 확진수
2020-01-24 2020-01-24 1.0
2020-01-25 2020-01-25 NaN
2020-01-26 2020-01-26 NaN
2020-01-27 2020-01-27 NaN
2020-01-28 2020-01-28 NaN
... ... ...
2021-12-22 2021-12-22 2719.0
2021-12-23 2021-12-23 2346.0
2021-12-24 2021-12-24 2123.0
2021-12-25 2021-12-25 1917.0
2021-12-26 2021-12-26 1496.0
필요 없는 컬럼을 제거하고 확진수가 결측치인 날은 확진자가 없었던 날이기 때문에 0으로 채워주고, 확진수 타입을 int로 변경한 후 cumsum()을 이용하여 누적 값을 구한다.
del df_all_day[0]
df_all_day = df_all_day.fillna(0)
df_all_day['확진수'] = df_all_day['확진수'].astype(int)
df_all_day["누적확진수"] = df_all_day['확진수'].cumsum()
df_all_day
# 실행 결과
확진수 누적확진수
2020-01-24 1 1
2020-01-25 0 1
2020-01-26 0 1
2020-01-27 0 1
2020-01-28 0 1
... ... ...
2021-12-22 2719 210764
2021-12-23 2346 213110
2021-12-24 2123 215233
2021-12-25 1917 217150
2021-12-26 1496 218646이렇게 구한 데이터프레임을 시각화해보자.
df_all_day.plot(ylim=(0, 250000))y축 범위 지정 : 0~25000
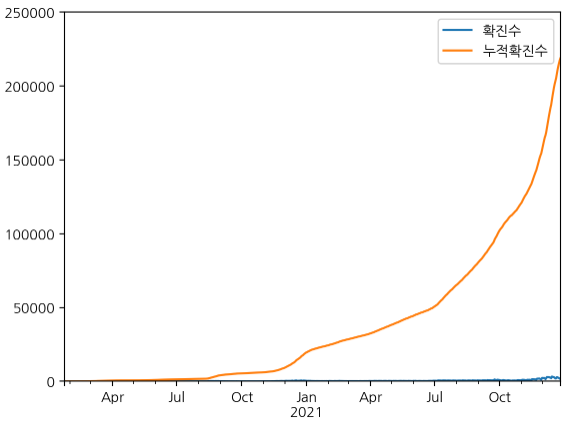
전체 기간의 데이터가 시각화 됐으나 누적 확진수에 비해 확진수의 스케일이 너무 작아 직관적이지 못하다.
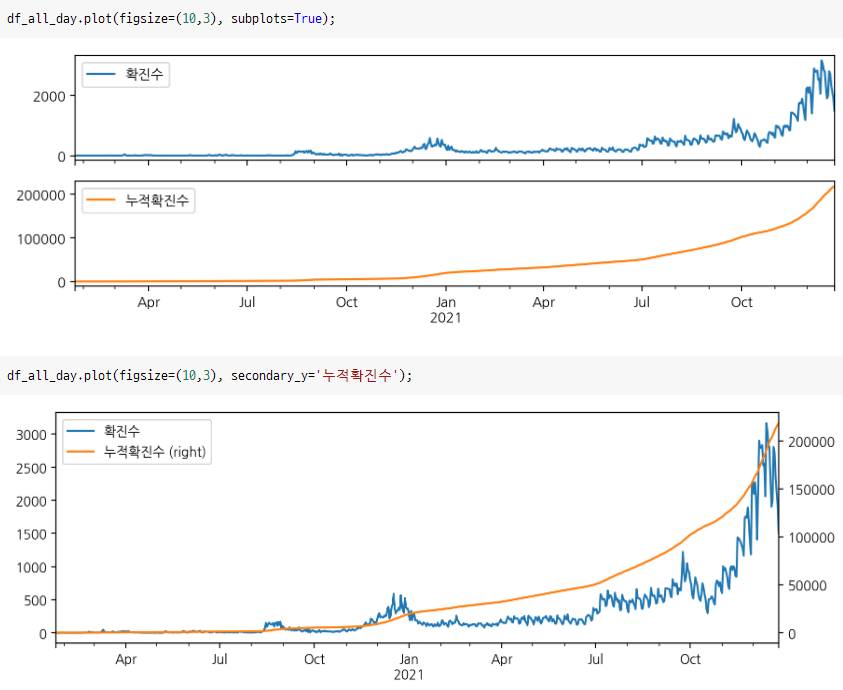
위와 같이 subplot을 사용하거나 2축 그래프를 통해 스케일 차이가 많이 나는 두 변수에 대해서도 직관적인 시각화를 할 수 있었다.
서울 각 구별 확진자 시각화
거주지 값들을 확인한다.
# 거주지 값 확인 : 공백이 포함되어있어서 처리 필요
df['거주지'].unique()
# 실행 결과
array(['강서구', '중랑구', '종로구', '마포구', '성북구', '타시도', '송파구', '서대문구', '성동구',
'서초구', '구로구', '강동구', '은평구', '관악구', '금천구', '노원구', '동작구', '강남구',
'양천구', '동대문구', '광진구', '기타', '영등포구', '도봉구', '용산구', '강북구', '중구',
'타시도 ', '양천구 ', '용산구 ', '동작구 ', '금천구 ', '마포구 ', '강동구 '],
dtype=object)공백이 포함되어 있는 항목이 있어 처리가 필요하다.
또한 "타시도"를 "기타"로 변경한 후 시각화를한다.
# "거주지" => "거주구"로 사본 생성
# 텍스트 앞뒤 공백 제거하기
df["거주구"] = df['거주지'].str.strip()
# 타시도 => 기타로 변경하기
df['거주구'] = df['거주구'].str.replace('타시도', '기타')
# "거주구" 빈도수 구하기
gu_count = df['거주구'].value_counts()
# gu_count 변수에 담긴 값 시각화 하기
gu_count.plot(kind='barh')
plt.axvline(5000, color='red', linestyle=':');barh는 수평(가로)막대그래프를 의미한다
axvline을 이용하여 특정 위치에 수직선을 표시할 수도 있다.
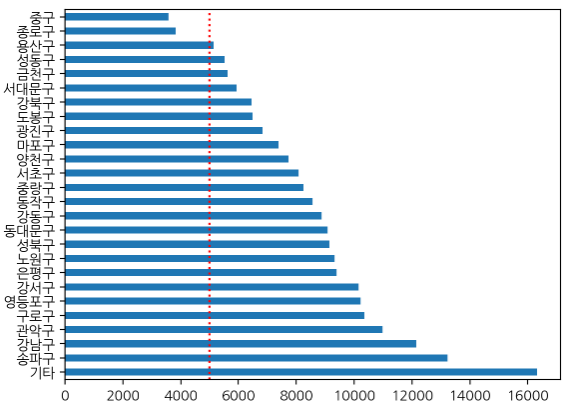
서울 코로나 확진자 데이터를 분석하고 시각화해보았다.
시각화를 하니 드디어 데이터분석을 하는 기분이 들었다.
'AI SCHOOL > TIL' 카테고리의 다른 글
| [DAY 26] 시가총액 상위 10종목 EDA - 주가추세, 수익률, pandas, matplotlib (0) | 2023.02.02 |
|---|---|
| [DAY 25] 서울시 코로나19 EDA - crosstab, str.contains와 isin, 데이터 시각화 (0) | 2023.02.01 |
| [DAY 23] SQL 집합연산, 서브쿼리, WITH, CTE (0) | 2023.01.27 |
| [DAY 22] SQL CASE, IF 조건분기, JOIN (0) | 2023.01.26 |
| [DAY 21] SQL 함수를 통해 숫자, 문자, 날짜 형태의 데이터 다루기, NULL 처리하기 (0) | 2023.01.25 |




댓글