네이버 증권 종목토론실에서 특정 종목을 선택하고 작성된 모든 게시물을 스크래핑하여 excel 파일로 저장한 후 확인해본다.
예시로 삼성전자를 보면 현재 80000페이지가 훌쩍 넘기 때문에 스크래핑을 진행할 종목은 가장 최근에 상장한 바이오노트(377740)로 선정한다.
먼저 필요한 라이브러리를 import한다.
import pandas as pd
import requests
import time
from tqdm import trange
from bs4 import BeautifulSoup as bs데이터 프레임을 만들기 위해 pandas,
URL로 요청을 보내기 위해 requests,
서버에 시간 간격을 두고 요청하기 위해 time,
진행 상황을 확인할 수 있는 trange,
종목토론실 마지막 페이지를 찾기 위해 BeautifulSoup
그리고 headers를 지정한다.
headers = {"user-agent": "Mozilla/5.0"}요청 후 정상적인 응답을 받기 위해서는 우리가 웹 데이터를 긁어가는 봇이 아니고 브라우저에서 요청을 보냈다는 것을 알려야한다. 이를 위해 headers를 지정하는 것이며, requests에 사용된다.
종목토론실 URL은 아래와 같다.
https://finance.naver.com/item/board.naver?code=000000&page=1
code= 부분에 종목 코드를 입력하고, page= 부분에 페이지 번호를 입력하면 해당 종목의 해당 페이지 URL이 되는 것이다. 이것을 파악하고 종목 코드와 페이지 번호를 파라미터로 입력받으면 종목토론실 URL을 반환하는 함수를 작성한다.
def get_url(item_code, page_no=1):
url = f"https://finance.naver.com/item/board.nhn"
url = f"{url}?code={item_code}&page={page_no}"
return url
하나의 페이지에 대한 글 목록을 스크래핑하는 함수
def get_one_page(item_code, page_no):
"한 페이지 수집"
# 종목 URL 만들기
url = get_url(item_code, page_no)
# requests
response = requests.get(url, headers=headers)
# 데이터프레임 만들기
table = pd.read_html(response.text)[1]
return table종목 코드와 페이지 번호를 받아 get_url 함수에 넘겨주어 url을 받고,
위에서 지정한 headers와 함께 GET 방식의 requests를 해서 응답을 받는다.
pandas의 read_html 함수는 table 태그의 내용만 가져온다.
그 값들이 리스트로 반환되는데, 그 중 1번 인덱스의 내용이 우리가 원하는 게시글 목록이다.
즉 get_one_page 함수는 한 페이지의 글 목록을 데이터프레임으로 반환한다.
해당 종목 종목토론실 마지막 페이지 번호를 구하는 함수
def get_last_page(item_code):
url = get_url(item_code)
response = requests.get(url, headers=headers)
html = bs(response.text)
last_page = int(html.select("#content > div.section.inner_sub > table > tbody > tr > td > table > tbody > tr > td.pgRR > a")[-1]['href'].split('=')[-1])
return last_page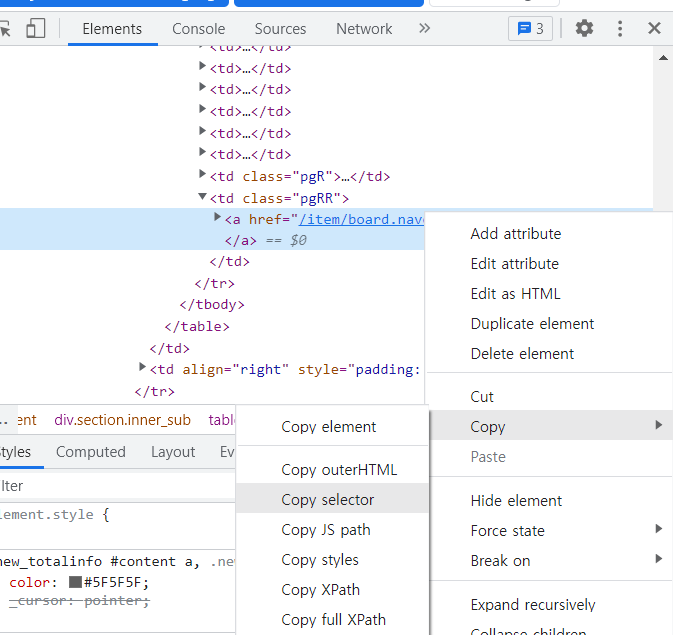
종목토론실 페이지에 들어가서 페이지 번호 선택 부분의 "맨뒤 ▶▶" 버튼에 우클릭 후 검사(inspect)를 클릭하면 위의 사진처럼 a태그가 하나 잡힐 것이다.
그 때 위의 사진처럼 우클릭 -> Copy -> Copy selector를 하면 BeautifulSoup의 select 함수에 인자로 넣을 #content > div.section.inner_sub > table:nth-child(3) > tbody > tr > td:nth-child(2) > table > tbody > tr > td.pgRR > a이 복사된다.
BeautifulSoup는 child 선택자인 nth-child를 지원하지 않기 때문에 이 부분을 지우고 활용한다.
함수 실행 결과
num = get_last_page("377740")
print(num)
# 실행 결과
151바이오노트의 종목 코드 377740을 아규먼트로 get_last_page 함수를 실행한 결과 현 시점 기준 바이오노트 종목토론실의 마지막 페이지인 151이 반환됨을 확인할 수 있다.
종목토론실 모든 게시물 스크래핑하는 함수
def get_all_pages(item_code):
"모든 페이지 수집"
last = get_last_page(item_code)
page_list = []
# 1페이지 ~ 끝페이지
for page_num in trange(1, last+1):
page = get_one_page(item_code, page_num)
page_list.append(page)
time.sleep(0.1)
# 모든 페이지 하나의 데이터프레임으로 합치기
df_all_page = pd.concat(page_list)
# 결측치 제거
df_all_page = df_all_page.dropna(how="all").iloc[:, :-1]
# 조회, 공감, 비공감 정수형 변환
df_all_page.loc[:, '조회':'비공감'] = df_all_page.loc[:, '조회':'비공감'].astype('int')
# 인덱스 리셋
df_all_page = df_all_page.reset_index(drop=True)
return df_all_page1. 위에서 만든 함수를 이용하여 입력한 종목 코드의 종목토론실의 마지막 페이지 번호를 구한다.
2. 1페이지부터 해당 페이지까지 모든 페이지의 데이터프레임을 page_list에 추가한다.
3. 하나의 데이터프레임으로 합친다.
4. 결측치를 제거하여 값이 있는 rows, columns만 남긴다.
5. 실수형으로 되어 있는 조회, 공감, 비공감 컬럼을 정수형으로 바꾼다.
6. reset_index를 이용하여 0부터 시작하는 인덱스를 새로 부여한다.
7. 모든 글이 들어간 데이터프레임을 반환한다.
함수 실행 결과
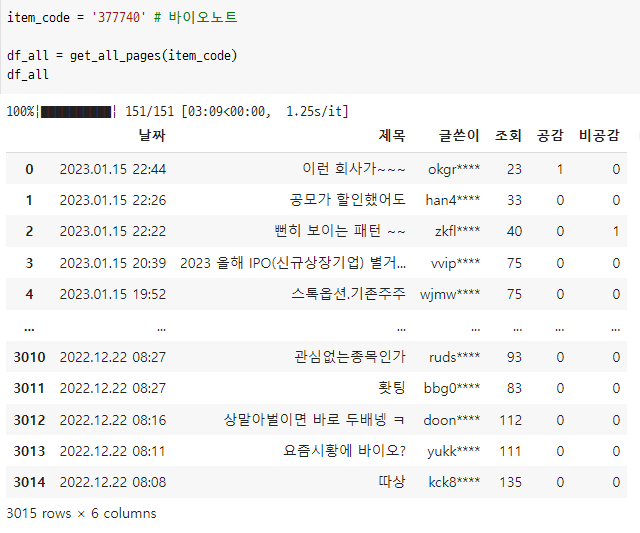
for loop에 사용한 trange로 인해 코드 실행이 얼마만큼 되었는지 실시간으로 0%~100%로 확인할 수 있고, 완료된 후에는 03분 09초가 걸려 실행이 완료되었음을 알 수 있다.
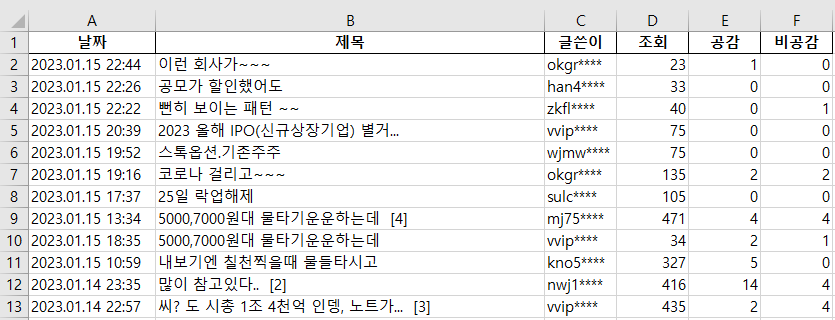
실행 결과 날짜, 제목, 글쓴이, 조회, 공감, 비공감 컬럼이 있는 3015 rows의 데이터프레임이 생성된 것을 볼 수 있다.
파일로 저장하기
이제 이렇게 웹 스크래핑을 통해 생성한 데이터프레임을 excel 파일로 저장해보자.
데이터프레임의 to_excel 메소드를 사용하면 된다.
df_all.to_excel('bionote.xlsx', index=False)
코드 실행 후 저장된 것 확인
excel을 이용해서 파일을 직접 열어서 확인
.
.
.
웹 스크래핑을 통해 바이오노트(377740)의 종목토론실 모든 게시물을 가져오고 excel 파일로 저장해 보았다.
전체 코드
import pandas as pd
import requests
import time
from tqdm import trange
from bs4 import BeautifulSoup as bs
headers = {"user-agent": "Mozilla/5.0"}
def get_url(item_code, page_no=1):
url = f"https://finance.naver.com/item/board.nhn"
url = f"{url}?code={item_code}&page={page_no}"
return url
def get_one_page(item_code, page_no):
"한 페이지 수집"
# 종목 URL 만들기
url = get_url(item_code, page_no)
# requests
response = requests.get(url, headers=headers)
# 데이터프레임 만들기
table = pd.read_html(response.text)[1]
return table
def get_last_page(item_code):
url = get_url(item_code)
response = requests.get(url, headers=headers)
html = bs(response.text)
last_page = int(html.select("#content > div.section.inner_sub > table > tbody > tr > td > table > tbody > tr > td.pgRR > a")[-1]['href'].split('=')[-1])
return last_page
def get_all_pages(item_code):
"모든 페이지 수집"
last = get_last_page(item_code)
page_list = []
# 1페이지 ~ 끝페이지
for page_num in trange(1, last+1):
page = get_one_page(item_code, page_num)
page_list.append(page)
time.sleep(0.1)
# 모든 페이지 하나의 데이터프레임으로 합치기
df_all_page = pd.concat(page_list)
# 결측치 제거
df_all_page = df_all_page.dropna(how="all").iloc[:, :-1]
# 조회, 공감, 비공감 정수형 변환
df_all_page.loc[:, '조회':'비공감'] = df_all_page.loc[:, '조회':'비공감'].astype('int')
# 인덱스 리셋
df_all_page = df_all_page.reset_index(drop=True)
return df_all_page
item_code = '377740' # 바이오노트
df_all = get_all_pages(item_code) # 20230116 00:00 기준 3015rows
df_all.to_excel('bionote.xlsx', index=False)
만약 종목토론실 스크래핑을 한다면 실행 날짜 기준으로 글 수가 적은 종목을 잘 선정해야한다.
눈에 보이는 아무거나 선정하면 데이터가 너무 많고 시간도 오래 걸릴 수 있다.
'Python' 카테고리의 다른 글
| Anaconda 설치부터 Jupyter Notebook 실행까지 차근차근 (0) | 2023.01.18 |
|---|---|
| [웹 스크래핑] 역대 대통령 연설기록 목록과 그 내용까지 (0) | 2023.01.16 |
| pseudo code(슈도코드, 의사코드)란? (0) | 2023.01.11 |
| [Python 이메일 발송] 파일 첨부하여 Gmail 보내기 (SMTP) (4) | 2023.01.08 |
| [예외처리] Exception Handling - try, except, else, finally, raise (0) | 2023.01.07 |




댓글